淘宝商品详情页数据采集攻略合集(2026合规版)
淘宝商品详情页数据采集需以合规性为核心,结合业务场景(临时测试、长期监控、批量集成)选择适配方案。以下整理 5 种主流方法,覆盖从新手到企业级的全场景需求,兼顾技术落地性与风险控制。
核心方案总览(快速选型)
| 方法 | 合规性 | 实时性 | 开发成本 | 适用场景 | 核心风险 |
|---|---|---|---|---|---|
| 淘宝开放平台官方 API | ✅ 完全合规 | 高(秒级) | 中(需申请权限) | 企业级批量采集、系统集成、长期监控 | 权限审核、调用配额限制 |
| 第三方合规数据接口 | ✅ 授权合规 | 中高(分钟级) | 低(开箱即用) | 新手快速落地、中小规模采集、临时项目 | 数据一致性依赖服务商、付费成本 |
| 无头浏览器渲染采集 | ⚠️ 灰色地带 | 中(秒级) | 高(需反爬适配) | 自定义字段采集、动态渲染页面解析 | 账号 / IP 封禁、违反平台协议 |
| 抓包工具临时采集 | ⚠️ 仅限个人测试 | 中(手动操作) | 极低(无需编码) | 单商品临时数据获取、接口分析 | 批量操作易触发风控、无自动化能力 |
| 淘宝联盟 API(淘客场景) | ✅ 合规(淘客权限) | 高 | 中 | 淘客选品、推广数据采集 | 仅限淘客相关场景、字段有限制 |
方法一:淘宝开放平台官方 API(企业级首选,绝对合规)
核心优势
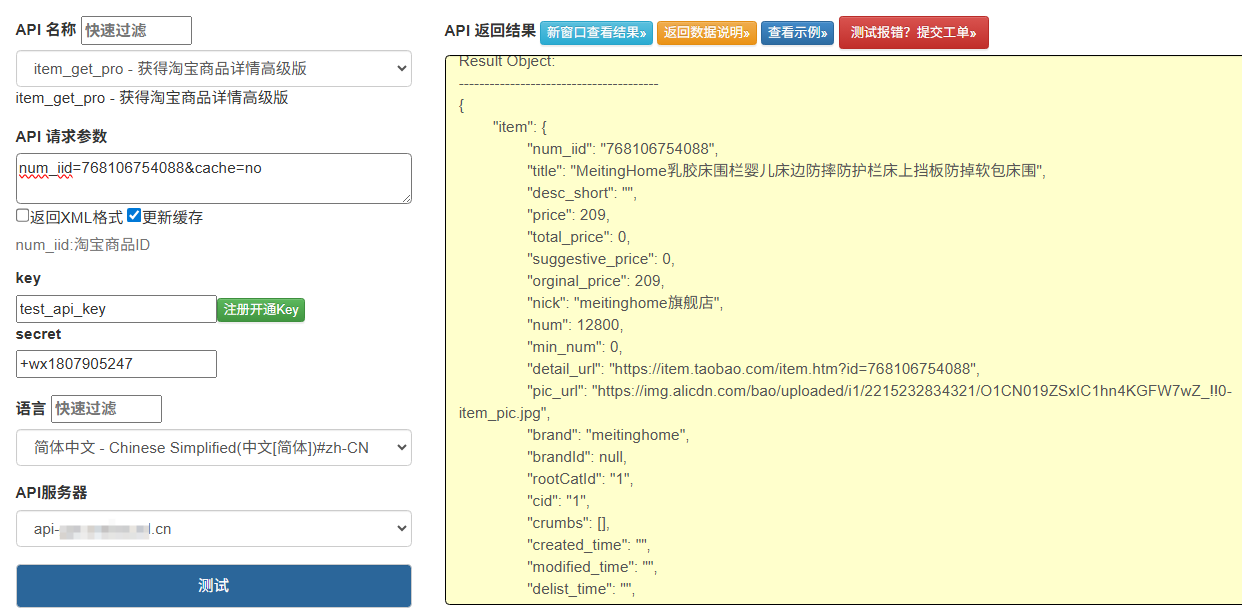
基于淘宝开放平台(TOP)的标准化接口,是唯一受官方认可的采集方式,数据准确率接近 100%,支持结构化 JSON 输出,无需解析复杂页面。
核心接口(2026 常用)
表格
| 接口名称 | 功能 | 必选参数 | 权限要求 |
|---|---|---|---|
taobao.item.get |
单商品详情采集 | num_iid(商品 ID)、fields(返回字段) |
个人 / 企业认证均可 |
taobao.item_get_batch |
批量商品采集(最多 50 个) | num_iids(商品 ID 列表) |
企业认证 + 场景说明 |
taobao.item_sku_get |
SKU 维度数据采集 | num_iid、sku_id |
企业认证 |
落地步骤(附 Python 示例)
账号与权限准备
登录,完成实名认证,创建应用(自用型 / 服务商型),获取
AppKey和AppSecret。申请对应接口权限(自用型基础权限 1-3 个工作日通过)。
核心代码实现(单商品采集)
最佳实践
字段按需选择:仅请求业务所需字段(如选品仅需
title,price,stock),减少带宽消耗。缓存策略:基础信息(标题、主图)缓存 24 小时,实时数据(价格、库存)缓存 5 分钟内。
异常处理:添加重试机制(3 次以内),处理配额超限、权限不足等错误。
方法二:第三方合规数据接口(新手首选,快速落地)
核心优势
第三方服务商(如聚美数科、OneBound)已完成官方 API 对接与权限申请,提供标准化 SDK/HTTP 接口,无需处理复杂的签名与权限问题,开箱即用。
适用场景
个人开发者快速搭建采集功能,无需企业资质。
临时项目需要快速获取数据,避免官方 API 审核周期。
中小规模采集(日调用量 < 1000 次)。
落地步骤
选择服务商:优先选择与淘宝官方合作的服务商,确认其具备合法授权。
注册与获取密钥:在服务商平台注册账号,获取 API Key。
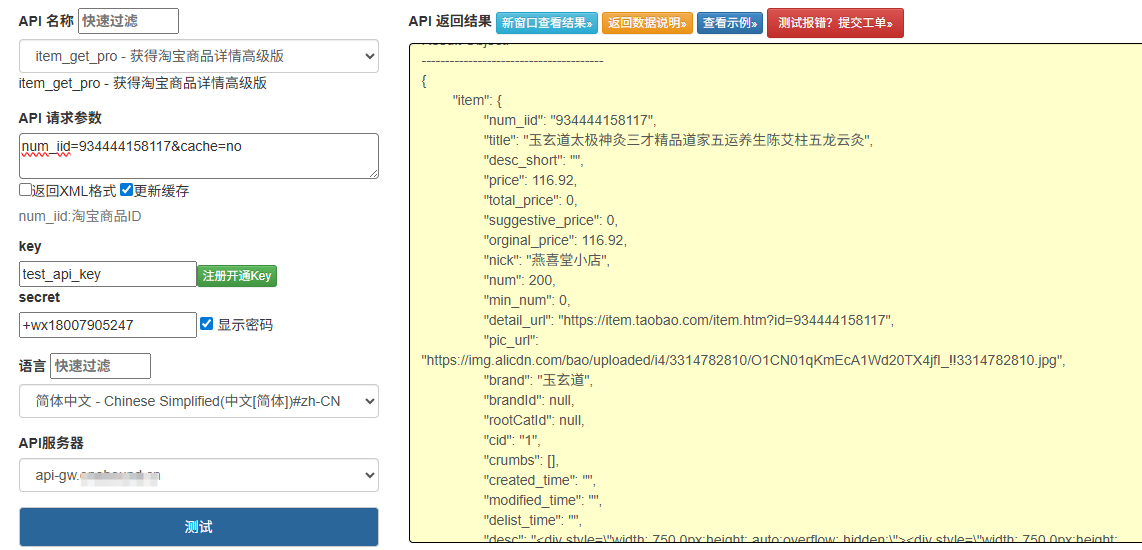
调用接口(以 OneBound 的
item_get为例):
注意事项
确认数据来源:要求服务商提供官方授权证明,避免使用非法爬虫聚合的接口。
控制成本:按需选择付费套餐(按调用量 / 包月),避免不必要的支出。
方法三:无头浏览器渲染采集(自定义场景,技术导向)
核心背景
淘宝详情页采用 Vue/React 动态渲染,核心数据(价格、SKU、库存)通过 JS 异步请求获取,直接爬取 HTML 无法获取完整数据,需通过无头浏览器模拟真实用户行为,渲染页面后提取数据。
核心工具
Playwright(推荐):资源占用低,支持多浏览器,内置反爬适配能力。
Selenium:生态成熟,适合复杂的页面交互模拟。
落地步骤(Playwright+Python)
安装依赖:
pip install playwright→playwright install chromium。核心代码(采集商品标题、价格、库存)
反爬适配关键(必做)
IP 池维护:使用高匿代理 IP(4G 移动代理最佳),避免单 IP 高频请求。
Cookie 鲜活度:通过扫码登录获取完整 Cookie,定期模拟用户行为(浏览、收藏)激活 Cookie。
行为模拟:添加随机请求间隔(1-3 秒),模拟鼠标轨迹、页面滚动等真实操作。
风险提示
此方法属于灰色地带,违反淘宝《用户协议》第 3.2 条,仅适用于个人技术研究或内部临时需求,禁止商用,否则可能面临账号封禁、法律追责。
方法四:抓包工具临时采集(手动测试,零开发)
核心优势
无需编码,通过浏览器开发者工具或第三方抓包工具(如 Charles、Fiddler),直接捕获淘宝详情页的核心 API 请求,提取 JSON 数据,适合单商品临时数据获取。
落地步骤(浏览器开发者工具,免费)
打开详情页:在 Chrome/Firefox 中打开淘宝商品详情页,按 F12 进入开发者工具。
抓包分析:
切换至「Network」面板,筛选「XHR/Fetch」类型。
刷新页面,找到核心接口(如
mtop.taobao.detail.getdetail)。提取数据:
点击接口,在「Response」面板查看 JSON 数据,直接复制所需字段(如
title、price、skus)。如需批量,可将接口 URL 保存,通过 Postman 批量请求(需携带 Cookie)。
适用场景
单个商品的临时数据核对(如价格、库存验证)。
核心 API 的参数分析(为爬虫开发做准备)。
注意事项
仅适用于个人非商用场景,批量请求易触发淘宝风控(滑块验证、IP 封禁)。
Cookie 有效期短(7-15 天),需定期重新获取。
方法五:淘宝联盟 API(淘客专属,合规采集)
核心优势
专为淘客场景设计,合规获取商品推广数据(含佣金、优惠券、推广链接),适合淘客选品、推广系统集成。
核心接口
taobao.tbk.item.get:获取淘客商品详情(含佣金比例)。taobao.tbk.item.recommend.get:获取商品推荐数据。
落地要求
注册淘宝联盟账号,完成淘客认证。
申请联盟 API 权限,获取
AppKey和AppSecret。调用时需携带淘客 PID(推广位 ID)。
2026 合规与反爬核心避坑指南
合规底线:商用场景必须选择淘宝开放平台官方 API 或第三方合规授权接口,禁止使用爬虫方式采集。
反爬重点:
避免高频请求:官方 API 遵守配额限制(免费版约 100 次 / 分钟),爬虫方式控制请求频率(<5 次 / 分钟 / IP)。
拒绝逆向破解:禁止对淘宝的
sign、_m_h5_tk等加密参数进行逆向解析,属于严重违规行为。数据使用:采集数据仅用于自身业务需求,禁止转售、泄露或用于恶意竞争。
方案选型最终建议
企业级长期项目:优先选择淘宝开放平台官方 API,确保合规性与稳定性。
新手 / 临时项目:选择第三方合规数据接口,快速落地,降低开发成本。
个人技术研究:可使用无头浏览器或抓包工具,但需严格遵守平台协议,禁止商用。
淘客场景:专属使用淘宝联盟 API,兼顾合规与业务需求。