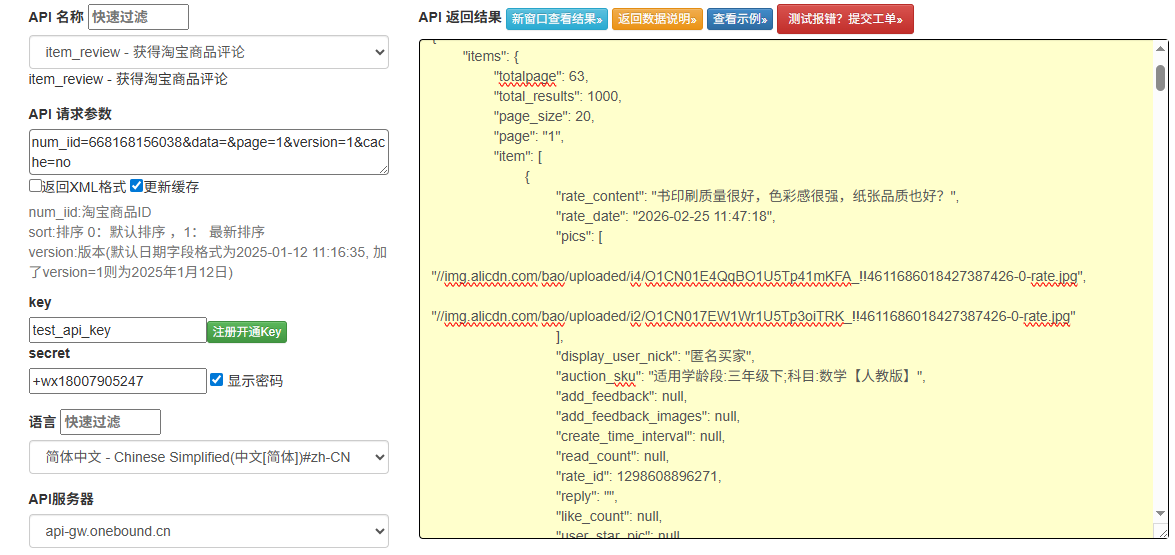
作为电商数据开发中最常用的接口之一,淘宝商品评论 API 是实现商品口碑分析、竞品监控、用户画像构建的核心能力。本文基于 Python 完整实现淘宝商品评论 API 的调用、数据解析、结构化存储全流程,代码可直接复用,配套详细注释和避坑指南,适合电商数据开发者、爬虫工程师、数据分析从业者参考。
一、淘宝商品评论 API 核心使用场景
在实际开发中,评论 API 是电商数据体系的基础模块,主要落地于以下场景:
1. 商品口碑与质量分析
批量抓取评论数据,通过 NLP 提取差评关键词(如 “续航差”“做工粗糙”)、统计评分分布,实现商品质量异常预警,替代人工逐条审核的低效模式。
2. 电商选品决策
为店群运营 / 供应链平台提供数据支撑:筛选好评率>95%、复购反馈多的潜力商品,规避差评集中的滞销款。
3. 竞品监控
定时抓取竞品评论,实时识别负面舆情(如 “售后差”“假货”),并推送告警通知,快速响应市场变化。
4. 内容运营与推荐
提取优质好评、晒单内容作为导购平台的素材,结合用户评价标签实现个性化商品推荐,提升转化。
5. AI 数据集构建
构建商品评论情感分析数据集,用于训练 NLP 模型(如文本分类、观点抽取),支撑智能客服、智能质检等场景。
二、API 调用前置知识(Python 版)
1. 接口通用规范(以主流第三方合规接口为例)
| 项⽬ |
说明 |
| 请求方式 |
POST/GET(推荐 POST,避免参数暴露) |
| 数据格式 |
JSON |
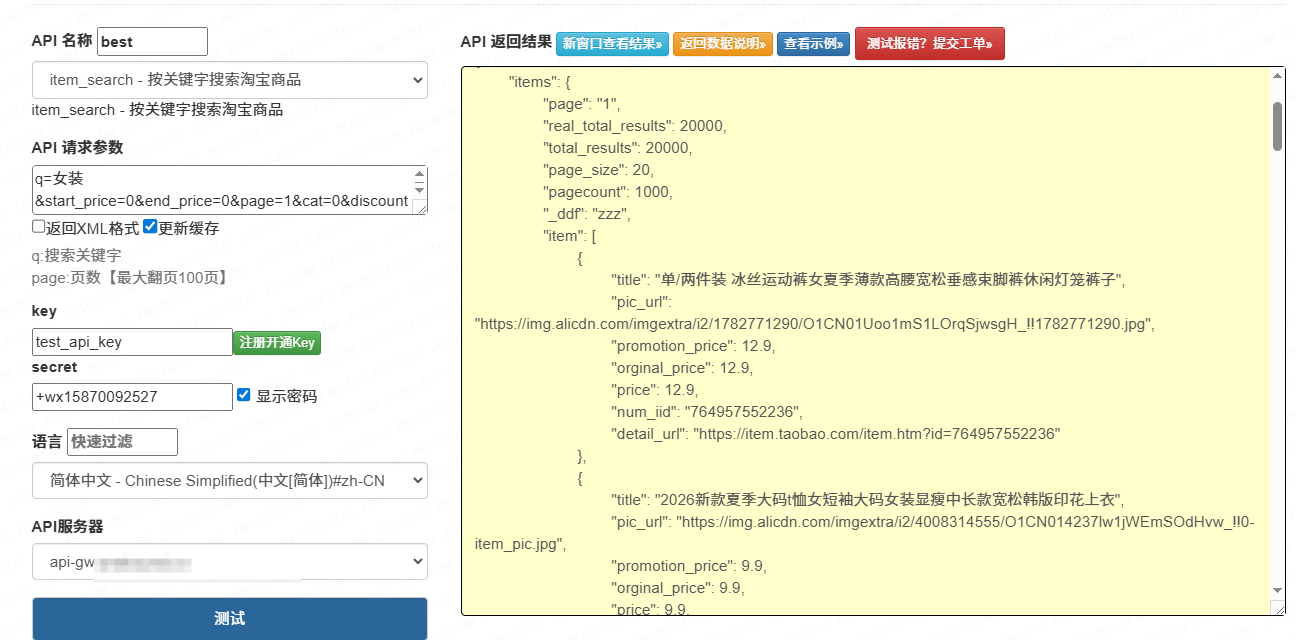
| 核心请求参数 |
appkey(应用密钥)、item_id(商品 ID)、page(页码)、page_size(每页条数)、sign(签名)、timestamp(时间戳) |
| 核心返回字段 |
user_name(用户名)、score(评分)、content(评论内容)、create_time(评论时间)、reply(商家回复)、total_count(总评论数) |
| 鉴权方式 |
appkey + appsecret 生成签名(MD5/SHA256) |
2. 环境准备
首先安装必备依赖,执行以下命令:
三、完整 Python 实战代码
1. 配置文件(.env)
新建 .env 文件存放敏感配置,避免硬编码泄露:
2. 核心实现代码(taobao_comment_api.py)
import requestsimport timeimport hashlibimport jsonimport osimport pymysqlfrom dotenv import load_dotenvfrom loguru import loggerfrom apscheduler.schedulers.blocking import BlockingSchedulerfrom requests.adapters import HTTPAdapterfrom urllib3.util.retry import Retry# 加载配置文件load_dotenv()# 初始化日志logger.add( "taobao_comment.log",
rotation="500MB",
retention="7 days",
encoding="utf-8",
level="INFO")class TaobaoCommentAPI: def __init__(self): """初始化配置和请求会话"""
# API 配置
self.app_key = os.getenv("APP_KEY")
self.app_secret = os.getenv("APP_SECRET")
self.api_url = os.getenv("API_URL")
self.page_size = int(os.getenv("PAGE_SIZE"))
self.max_retry = int(os.getenv("MAX_RETRY"))
# MySQL 配置
self.mysql_config = { "host": os.getenv("MYSQL_HOST"), "port": int(os.getenv("MYSQL_PORT")), "user": os.getenv("MYSQL_USER"), "password": os.getenv("MYSQL_PASSWORD"), "db": os.getenv("MYSQL_DB"), "charset": "utf8mb4" # 支持emoji
}
# 初始化请求会话(带重试机制)
self.session = self._init_session()
# 初始化数据库连接
self.db_conn = self._init_mysql() def _init_session(self): """初始化请求会话,配置超时和重试"""
session = requests.Session() # 重试策略:连接失败、超时、5xx错误重试
retry_strategy = Retry(
total=self.max_retry,
backoff_factor=1, # 重试间隔:1s, 2s, 4s...
status_forcelist=[429, 500, 502, 503, 504],
allowed_methods=["GET", "POST"]
)
adapter = HTTPAdapter(max_retries=retry_strategy)
session.mount("https://", adapter)
session.mount("http://", adapter) # 设置超时时间
session.timeout = 10
return session def _init_mysql(self): """初始化MySQL连接,创建评论表(如果不存在)"""
try:
conn = pymysql.connect(**self.mysql_config) # 创建表
create_table_sql = """
CREATE TABLE IF NOT EXISTS tb_comment (
id INT AUTO_INCREMENT PRIMARY KEY COMMENT '自增ID',
item_id VARCHAR(64) NOT NULL COMMENT '商品ID',
user_name VARCHAR(64) COMMENT '用户名',
score TINYINT COMMENT '评分(1-5)',
content TEXT COMMENT '评论内容',
create_time DATETIME COMMENT '评论时间',
reply_content TEXT COMMENT '商家回复',
has_image TINYINT DEFAULT 0 COMMENT '是否有图片(0-无,1-有)',
crawl_time DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '抓取时间',
UNIQUE KEY uk_item_user_time (item_id, user_name, create_time) # 防止重复存储
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='淘宝商品评论表';
"""
with conn.cursor() as cursor:
cursor.execute(create_table_sql)
conn.commit()
logger.info("MySQL连接成功,评论表初始化完成") return conn except Exception as e:
logger.error(f"MySQL初始化失败:{str(e)}") raise
def _generate_sign(self, params): """生成API签名(MD5方式,按接口要求调整)"""
# 1. 按key排序参数
sorted_params = sorted(params.items(), key=lambda x: x[0]) # 2. 拼接参数字符串
sign_str = ""
for k, v in sorted_params: if v: # 跳过空值
sign_str += f"{k}{v}"
# 3. 拼接app_secret
sign_str = self.app_secret + sign_str + self.app_secret # 4. MD5加密并转大写
sign = hashlib.md5(sign_str.encode("utf-8")).hexdigest().upper() return sign def get_comments(self, item_id, page=1): """
调用API获取单页评论
:param item_id: 商品ID
:param page: 页码
:return: 结构化的评论列表
"""
try: # 1. 构造基础参数
timestamp = str(int(time.time()))
params = { "appkey": self.app_key, "item_id": item_id, "page": page, "page_size": self.page_size, "timestamp": timestamp
} # 2. 生成签名
params["sign"] = self._generate_sign(params)
# 3. 发送请求
response = self.session.post(self.api_url, json=params)
response.raise_for_status() # 抛出HTTP错误
result = response.json()
# 4. 校验返回结果
if result.get("code") != 200:
logger.error(f"API调用失败:{result.get('msg')},商品ID:{item_id},页码:{page}") return []
# 5. 解析评论数据
comments = result.get("data", {}).get("comments", [])
parsed_comments = [] for comment in comments:
parsed_comment = { "item_id": item_id, "user_name": comment.get("user_name", ""), "score": comment.get("score", 0), "content": comment.get("content", "").strip(), "create_time": comment.get("create_time", ""), "reply_content": comment.get("reply", {}).get("content", "").strip(), "has_image": 1 if comment.get("images") else 0
}
parsed_comments.append(parsed_comment)
logger.info(f"成功抓取商品{item_id}第{page}页评论,共{len(parsed_comments)}条") return parsed_comments
except requests.exceptions.RequestException as e:
logger.error(f"请求异常:{str(e)},商品ID:{item_id},页码:{page}") return [] except Exception as e:
logger.error(f"解析异常:{str(e)},商品ID:{item_id},页码:{page}") return [] def save_comments(self, comments): """
保存评论到MySQL
:param comments: 解析后的评论列表
"""
if not comments: return
try:
insert_sql = """
INSERT INTO tb_comment
(item_id, user_name, score, content, create_time, reply_content, has_image)
VALUES (%s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
score=VALUES(score), content=VALUES(content), reply_content=VALUES(reply_content);
"""
with self.db_conn.cursor() as cursor: # 批量插入
cursor.executemany(
insert_sql,
[(
c["item_id"], c["user_name"], c["score"],
c["content"], c["create_time"], c["reply_content"], c["has_image"]
) for c in comments]
)
self.db_conn.commit()
logger.info(f"成功保存{len(comments)}条评论到MySQL") except Exception as e:
self.db_conn.rollback()
logger.error(f"保存评论失败:{str(e)}") def crawl_item_comments(self, item_id, max_page=5): """
抓取单个商品多页评论
:param item_id: 商品ID
:param max_page: 最大抓取页数
"""
logger.info(f"开始抓取商品{item_id}评论,最大页数:{max_page}") for page in range(1, max_page + 1):
comments = self.get_comments(item_id, page) if not comments:
logger.warning(f"商品{item_id}第{page}页无评论,停止抓取") break
self.save_comments(comments) # 限速,避免触发接口限流
time.sleep(1) def start_scheduled_crawl(self, item_ids, max_page=5, cron="0 0 * * *"): """
启动定时抓取(每天0点执行)
:param item_ids: 商品ID列表
:param max_page: 最大抓取页数
:param cron: cron表达式
"""
scheduler = BlockingScheduler(timezone="Asia/Shanghai") # 添加定时任务
scheduler.add_job(
func=self._scheduled_task,
trigger="cron",
args=[item_ids, max_page],
cron_expression=cron,
name="淘宝评论定时抓取"
)
logger.info("定时抓取任务已启动,Cron表达式:{},监控商品:{}", cron, item_ids) try:
scheduler.start() except KeyboardInterrupt:
logger.info("定时任务被手动终止")
scheduler.shutdown() def _scheduled_task(self, item_ids, max_page): """定时任务执行函数"""
for item_id in item_ids:
self.crawl_item_comments(item_id, max_page) def close(self): """关闭数据库连接和会话"""
if self.db_conn:
self.db_conn.close()
self.session.close()
logger.info("资源已释放(数据库连接、请求会话)")# 测试代码if __name__ == "__main__": # 初始化API客户端
comment_api = TaobaoCommentAPI()
try: # 1. 单次抓取指定商品评论(示例:商品ID替换为实际值)
target_item_id = "123456789"
comment_api.crawl_item_comments(target_item_id, max_page=3)
# 2. 启动定时抓取(注释掉单次抓取,打开下面的代码即可)
# monitor_item_ids = ["123456789", "987654321"]
# comment_api.start_scheduled_crawl(monitor_item_ids, max_page=5)
finally: # 确保资源释放
comment_api.close()3. 代码运行效果说明
执行代码后,你会看到以下效果:
日志输出:taobao_comment.log 文件中会记录抓取进度、成功 / 失败信息;
数据库存储:MySQL 的 taobao_comment 表中会新增商品评论数据,重复评论会自动更新;
单次抓取:快速获取指定商品 3 页评论(可调整 max_page);
定时抓取:注释掉单次抓取代码,打开定时任务后,每天 0 点自动抓取指定商品评论。
4. 常见问题与避坑指南
| 问题现象 |
原因分析 |
解决方案 |
| 签名验证失败 |
签名生成规则与接口要求不一致 |
核对接口文档,调整 _generate_sign 函数 |
| 接口返回 429 |
请求频率过高触发限流 |
增加 time.sleep() 间隔,降低抓取速度 |
| 评论内容乱码 |
编码未设置为 utf8mb4 |
MySQL 表字符集必须为 utf8mb4(支持 emoji) |
| 数据库连接失败 |
配置错误 / 服务未启动 |
检查 .env 文件中的 MySQL 配置,启动 MySQL |
| 接口返回空数据 |
商品 ID 错误 / 无评论 / 接口权限不足 |
核对商品 ID,检查接口权限 |
四、开发者核心注意事项(CSDN 重点提醒)
1. 合规性(重中之重)
仅使用合规授权的 API 接口,禁止爬取淘宝官方未开放的接口;
评论数据仅限内部分析 / 商用授权场景,禁止泄露用户隐私、用于非法用途;
遵守《电子商务法》《网络数据安全管理条例》等法律法规。
2. 稳定性优化
加入熔断降级:当 API 连续失败时,暂停抓取,避免无效请求;
增加缓存:对高频访问的商品评论做本地缓存,减少 API 调用;
监控告警:对接钉钉 / 企业微信机器人,异常时推送告警信息。
3. CSDN 读者专属优化建议
多语言适配:如需 Java/PHP 版本,可参考本文的签名、解析逻辑,替换 HTTP 客户端即可;
数据可视化:结合 pandas + matplotlib 实现评论评分分布、关键词云图;
分布式部署:如需大规模抓取,可基于 Celery + Redis 实现分布式任务调度。
五、总结
本文基于 Python 实现了淘宝商品评论 API 的完整调用链路,核心要点如下:
通过配置文件管理敏感信息,符合开发最佳实践;
封装通用 API 调用类,支持单次抓取、定时抓取两种模式;
完善的异常处理、重试机制,保证抓取稳定性;
结构化存储到 MySQL,支持重复数据自动更新;
附带避坑指南,解决开发者常见问题。