大规模调用淘宝商品详情 API 的分布式请求调度实践
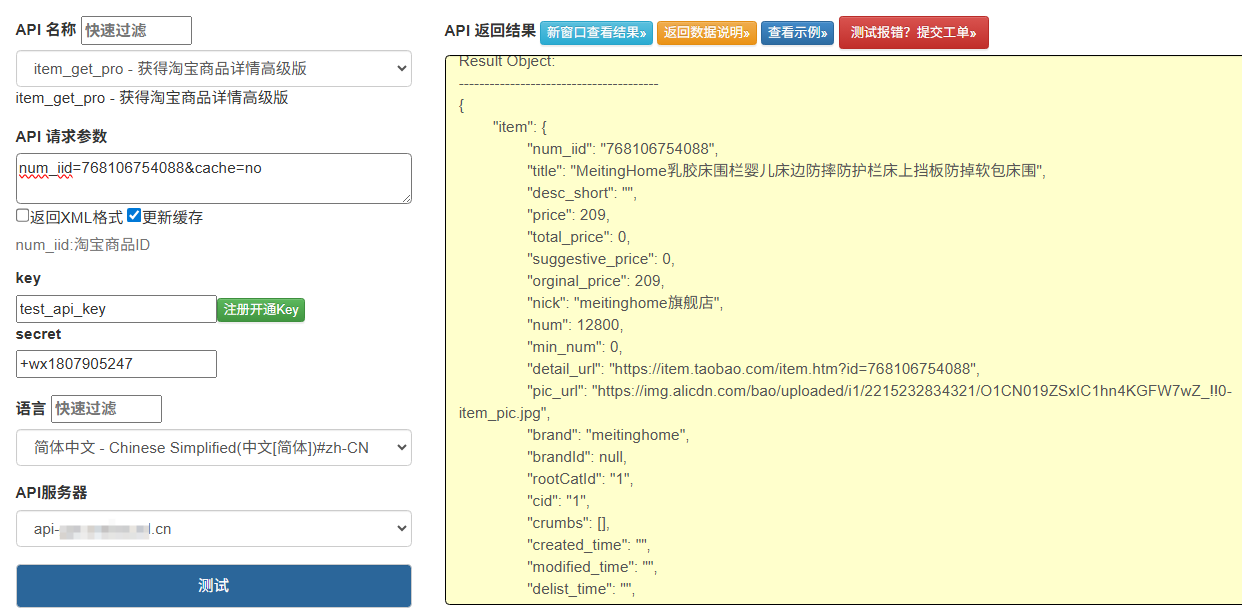
在电商数据分析、比价系统、选品工具等业务场景中,往往需要大规模调用淘宝商品详情 API 以获取商品标题、价格、销量、评价等核心数据。然而,面对淘宝开放平台的严格限流策略、海量商品 ID 的处理需求以及系统高可用要求,传统的单节点调用方式早已力不从心。本文将从实践角度出发,分享一套成熟的分布式请求调度方案,探讨如何在合规前提下实现高效、稳定、可扩展的 API 调用体系。
一、大规模调用的核心挑战
在着手设计分布式调度系统前,我们必须先明确淘宝商品详情 API 调用的核心约束与技术难点:
平台限流约束
淘宝开放平台对 API 调用实施多层次限制:单 AppKey 的 QPS 限制(通常为 10-100 次 / 秒)、IP 维度的并发限制、单日调用总量阈值,以及针对高频访问相同商品 ID 的特殊管控。任何单一节点都无法突破这些限制,反而容易触发临时封禁。海量任务处理压力
当需要处理百万级甚至千万级商品 ID 时,单节点的网络 IO、连接池管理、任务队列都会成为瓶颈,导致任务积压、超时失败率上升。分布式协调难题
多节点间如何分配任务以避免重复调用?如何动态调整各节点的请求频率以适应平台限流变化?如何在节点故障时实现任务自动迁移?数据一致性与可靠性
API 调用可能因网络波动、平台临时维护等原因失败,需要设计重试机制;同时,部分商品可能因下架、隐私设置等原因无法获取数据,需建立异常处理规范。
二、分布式调度系统架构设计
针对上述挑战,我们设计了一套 "四层架构" 的分布式请求调度系统,通过分层解耦实现高可用与可扩展性:
1. 任务管理层(Task Manager)
核心功能:接收上层业务系统的批量任务(商品 ID 列表),进行任务拆分、优先级排序与元数据存储。
实现方案:
采用分片策略将海量商品 ID 均匀分配到不同任务组,每个任务组包含 1000-5000 个商品 ID,便于节点并行处理。
基于 Redis 的 Sorted Set 实现任务优先级队列,支持按业务紧急程度(如实时比价任务 > 历史数据补全任务)动态调整执行顺序。
存储任务状态(待处理 / 处理中 / 已完成 / 失败)与进度,通过定时任务巡检超时任务。
2. 资源调度层(Resource Scheduler)
核心功能:管理 API 调用资源(AppKey、IP 代理池),动态分配任务给执行节点,实施全局限流。
关键设计:
AppKey 池化管理:维护多组 AppKey,每组对应独立的限流配额,通过权重动态分配调用量(如高配额 AppKey 承担更多任务)。
IP 代理动态切换:整合第三方代理服务,为每个执行节点分配独立 IP,避免单 IP 触发限流;同时监控代理存活率,自动剔除无效 IP。
分布式限流算法:基于 Redis 实现令牌桶算法,全局控制 QPS。例如,若总配额为 1000 QPS,则每 100ms 向令牌桶投放 100 个令牌,执行节点需获取令牌后才能发起调用。
3. 执行节点层(Worker Nodes)
核心功能:实际执行 API 调用,处理响应数据,上报执行结果。
优化策略:
连接池复用:使用 HttpClient 连接池管理与淘宝 API 服务器的长连接,设置合理的最大连接数(如每个节点 50-100)与超时时间(连接超时 3 秒,读取超时 10 秒)。
本地任务队列:每个 Worker 节点维护内存级任务队列(如基于 Disruptor 的无锁队列),缓冲从资源调度层获取的任务,避免频繁请求调度中心。
失败重试机制:对因网络超时、5xx 错误导致的失败任务,采用指数退避策略重试(如首次间隔 1 秒,第二次 2 秒,最多重试 3 次);对 403、429 等限流错误,直接标记为 "需调度层协调"。
4. 数据存储层(Data Storage)
核心功能:存储 API 返回的商品详情数据与调用日志,支持后续分析与回溯。
存储方案:
商品结构化数据(价格、销量等)存入 MySQL 分库分表,按商品 ID 哈希分片。
原始响应 JSON 与调用日志(时间、耗时、状态码)存入 Elasticsearch,便于问题排查与调用趋势分析。
热点商品数据(如近 24 小时内多次查询的商品)缓存至 Redis,过期时间设为 1 小时,减少重复调用。
三、关键技术难点与解决方案
1. 动态限流适配
淘宝开放平台的限流策略可能动态调整(如大促期间收紧限制),静态配置的 QPS 阈值容易导致频繁触发限流。解决方案如下:
实时监控限流状态:解析 API 返回的响应头(如
X-RateLimit-Remaining),实时计算剩余配额,当剩余量低于 20% 时自动降低调用频率。自适应调整算法:基于最近 5 分钟的平均失败率(限流错误占比)动态调整令牌生成速度。例如,失败率 > 10% 时,临时降低 20% 的 QPS 配额;失败率 < 1% 时,逐步恢复至基准值。
2. 任务幂等性保障
分布式系统中,任务重复执行可能导致 API 调用次数浪费(尤其对收费 API)。需通过双重机制确保幂等:
前置校验:Worker 节点获取任务后,先查询 Redis 的 "正在处理" 集合,若商品 ID 已存在则拒绝执行。
后置标记:调用成功后,立即将商品 ID 写入 "已处理" 集合(过期时间 24 小时),避免短期内重复调用。
3. 节点弹性伸缩
根据任务量自动扩缩容是应对流量波动的关键:
扩容触发:当任务队列积压量超过阈值(如总任务数的 30%)或平均等待时间 > 5 分钟时,通过 K8s API 自动增加 Worker 节点副本数。
缩容策略:当节点空闲时间持续 10 分钟且队列任务量低于阈值时,逐步减少节点,避免资源浪费。
四、性能与稳定性优化实践
经过实际业务验证,我们的分布式调度系统在处理 100 万商品 ID 时,可实现以下指标:
平均调用成功率:99.2%(剔除因商品本身不可访问导致的失败)
峰值处理能力:1200 次 / 秒(基于 20 个 Worker 节点与 10 组 AppKey)
单商品平均处理耗时:800ms(含网络传输与数据存储)
关键优化手段包括:
预热机制:新启动的 Worker 节点先以 50% 的基准 QPS 运行,逐步提升至 100%,避免瞬间流量冲击导致限流。
降级策略:当 API 调用失败率突增(如 > 30%)时,自动降级为 "核心字段优先获取" 模式,减少请求数据量以提高成功率。
日志埋点与监控:通过 Prometheus 采集节点存活数、QPS、失败率等指标,结合 Grafana 可视化;设置关键指标告警(如失败率 > 5% 时短信通知)。
五、合规性与风险提示
在大规模调用淘宝 API 时,需严格遵守平台规范,避免触发封号风险:
确保所有调用均通过官方开放平台进行,不使用爬虫模拟登录等违规手段。
合理设置请求间隔,避免对同一商品 ID 在短时间内高频调用(建议间隔≥30 分钟)。
数据用途符合《淘宝开放平台服务协议》,不将获取的商品数据用于商业竞争或未经授权的分发。
六、总结与展望
分布式请求调度系统通过资源池化、动态限流、任务分片等技术,有效解决了淘宝商品详情 API 大规模调用的难题,为电商数据分析类业务提供了稳定的数据获取能力。未来可进一步探索:
基于机器学习预测 API 限流规律,实现更智能的请求调度;
引入边缘计算节点,将部分调用任务部署在离淘宝 API 服务器更近的区域,降低网络延迟;
构建 API 调用健康度评分体系,对不同 AppKey、IP 代理进行量化评估,优化资源分配。
在技术实践中,平衡 "效率" 与 "合规" 始终是核心原则 —— 只有在遵守平台规则的前提下,才能实现系统的长期稳定运行。