淘宝商品详情页公开数据的爬取全过程分享|已封装API分享
一、引言:爬取背景与合规声明
在电商运营、竞品分析、市场调研等场景中,淘宝商品详情页的公开数据(如商品标题、价格、销量、详情图等)具有重要参考价值。但需明确:本文仅针对淘宝平台公开可访问的数据,爬取过程严格遵守《网络安全法》《电子商务法》等法律法规,不侵犯用户隐私与平台商业秘密,且需遵守淘宝平台《robots 协议》及用户服务条款,禁止高频次、大规模爬取影响平台正常运营。
本文将完整分享从环境搭建、接口分析、数据爬取到 API 封装的全流程,并提供可直接使用的封装 API 示例,帮助技术开发者快速实现合法的数据获取需求。
二、前期准备:环境与工具搭建
2.1 开发环境配置
推荐使用 Python 3.8 + 版本(兼容性强、生态完善),核心依赖库如下:
2.2 关键参数准备
爬取淘宝商品数据需提前获取 3 类核心参数,且需通过个人正常账号操作,禁止盗用他人信息:
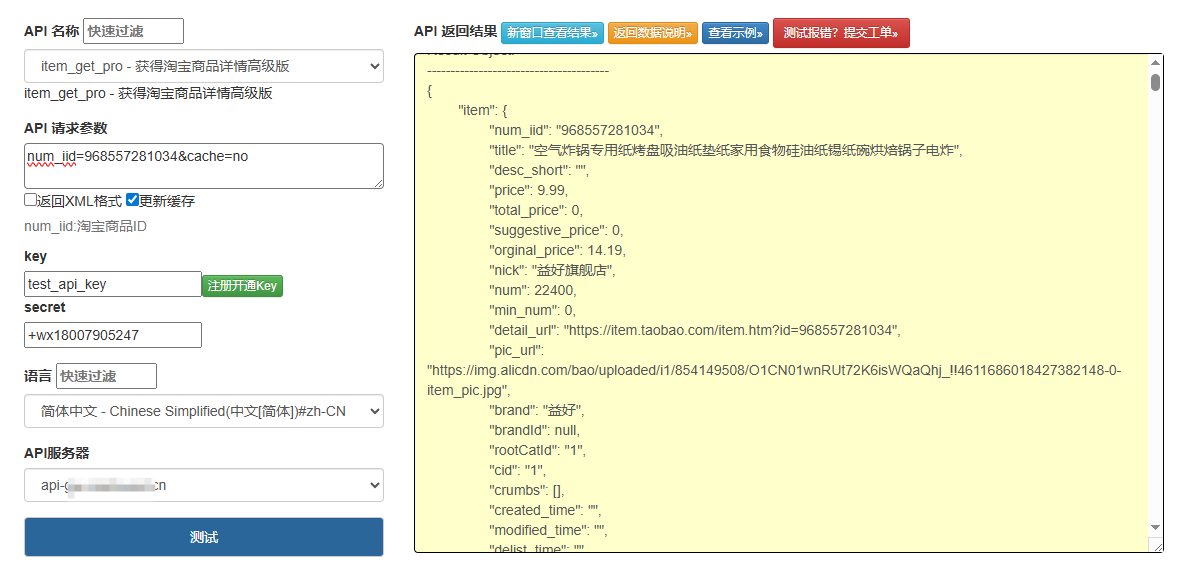
商品 ID(num_iid):从淘宝商品详情页 URL 中提取,例如,其中123456789即为商品 ID。
User-Agent:模拟浏览器请求,避免被识别为爬虫。可在 Chrome 浏览器按F12→Network→任意请求→Headers中复制User-Agent,示例:
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36
Cookie:用于验证用户身份(淘宝部分公开数据需登录态)。同样在浏览器Network请求的Headers中复制Cookie,注意定期更新(Cookie 有效期约 7-15 天)。
2.3 抓包工具使用
需通过浏览器开发者工具分析淘宝商品数据接口,步骤如下:
打开淘宝商品详情页,按F12打开开发者工具,切换至Network标签;
刷新页面,筛选XHR请求(淘宝动态数据多通过 XHR 加载);
在请求列表中搜索含item或detail的关键词(如item_get类请求),找到返回商品核心数据的接口(Response 格式为 JSON);
记录该接口的Request URL、Request Method(通常为 GET)及请求参数(如num_iid、timestamp等)。
三、核心爬取过程:从接口分析到数据提取
3.1 接口分析:定位公开数据接口
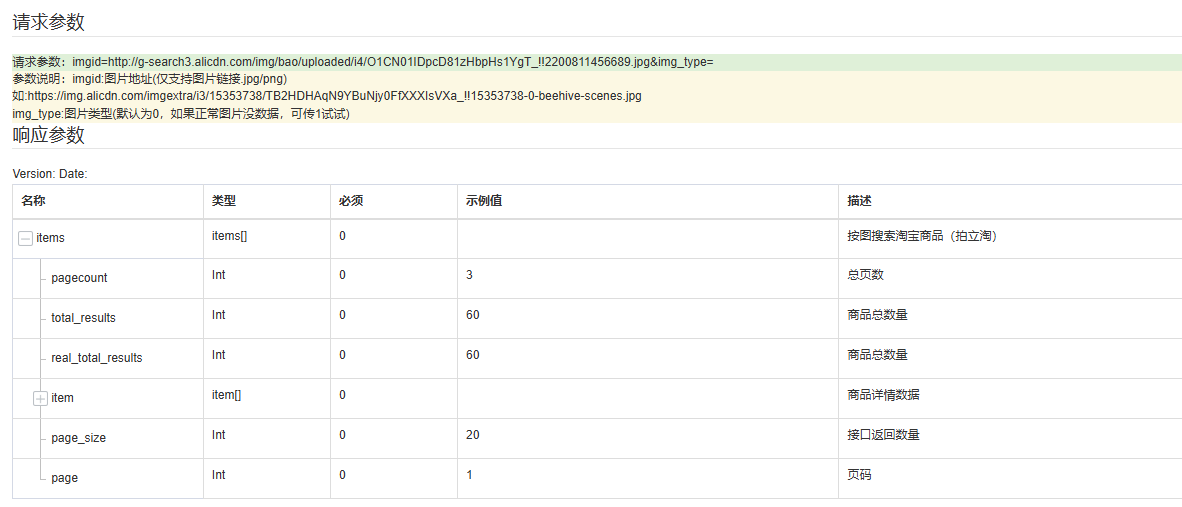
通过抓包可发现,淘宝商品详情页的公开数据多通过固定格式接口返回,以常见的 “商品基础信息接口” 为例(接口可能随平台更新变化,需重新抓包确认):
接口 URL:
请求方法:GET
核心参数:
|
参数名 |
说明 |
示例值 |
|
num_iid |
商品 ID |
123456789 |
|
type |
数据类型 |
item |
|
dataType |
响应格式 |
json |
|
timestamp |
时间戳(毫秒级) |
1695345678901 |
注意:淘宝部分接口会对参数进行签名(如sign),但公开数据接口的签名逻辑通常可通过浏览器请求反向推导(或使用登录后的 Cookie 绕过部分验证),本文不涉及破解加密算法,仅基于公开可访问的接口参数。
3.2 请求发送与异常处理
使用requests库发送请求,需加入异常处理(如网络超时、请求被拒、参数错误等),代码示例:
3.3 数据解析与提取
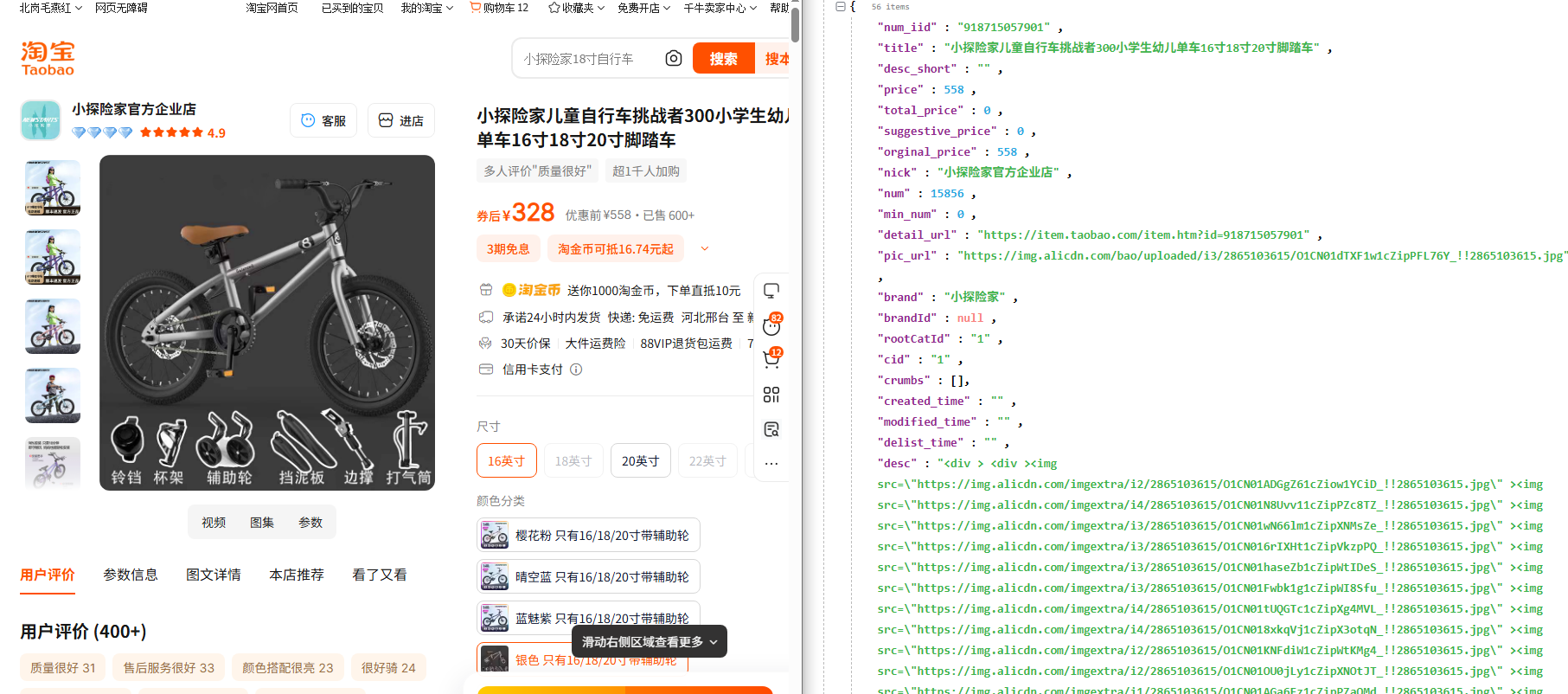
接口返回的商品数据包含大量字段,需根据需求提取关键信息(如标题、价格、销量等),示例:
四、API 封装实战:用 FastAPI 对外提供服务
为方便团队或其他系统调用,将爬取逻辑封装为 HTTP API,使用 FastAPI 实现(支持自动生成接口文档、参数验证等功能)。
4.1 API 封装代码
创建文件,代码如下:
4.2 API 测试与使用
启动服务:
python main.py
访问接口文档:打开浏览器访问,可看到自动生成的 API 文档,支持在线测试;
调用示例:
curl 命令:
curl "http://127.0.0.1:8000/api/taobao/item?num_iid=123456789&client_ip=192.168.1.100"
返回结果:
{
"code": 200,
"message": "success",
"data": {
"商品ID": "123456789",
"商品标题": "2024新款夏季短袖T恤男纯棉宽松百搭上衣",
"现价": "59.9",
"原价": "99.9",
"销量": "10000+",
"店铺名称": "XX男装旗舰店",
"详情图URL列表": ["https://img.alicdn.com/imgextra/i1/xxx.jpg", ...],
"主图URL列表": ["https://img.alicdn.com/imgextra/i2/xxx.jpg", ...]
}
}
五、反爬应对与合规要点
5.1 反爬措施(降低被封禁风险)
控制请求频率:如 API 中设置的 “每分钟 60 次” 限制,避免短时间内大量请求;
IP 轮换:若需大规模爬取,可使用合法代理 IP 池(避免使用黑产 IP),每次请求切换 IP;
UA 随机化:维护多个浏览器的 User-Agent 列表,每次请求随机选择;
模拟真实行为:在请求间加入随机延迟(如 1-3 秒),避免机械性请求;
定期更新 Cookie:Cookie 过期后及时通过正常登录更新,避免使用失效 Cookie。
5.2 合规风险提示
数据用途合法:爬取的公开数据仅可用于自身分析、研究,禁止用于商业售卖、恶意竞争等违法场景;
遵守 robots 协议:访问,确认允许爬取的路径(淘宝对部分商品数据可能限制爬取);
保护账号安全:避免使用同一账号频繁爬取,防止账号被封禁;
应对平台更新:淘宝接口可能随时调整,若爬取失败需重新抓包分析接口,禁止暴力破解。
六、常见问题与解决方案
|
问题现象 |
可能原因 |
解决方案 |
|
接口返回 403 Forbidden |
被识别为爬虫(UA/Cookie 异常) |
更新 Cookie、更换 UA、降低请求频率 |
|
商品数据为空 |
商品 ID 错误或商品已下架 |
验证商品 ID 有效性,检查商品是否可正常访问 |
|
API 调用提示 429 |
请求频率超过限制 |
等待 1 分钟后再试,或调整 MAX_REQUESTS_PER_MINUTE |
|
响应格式解析失败 |
淘宝接口更新 |
重新抓包分析新接口的参数与响应格式 |
七、总结与展望
本文完整分享了淘宝商品详情页公开数据的爬取流程:从环境搭建、接口分析、数据提取到 API 封装,核心在于合规性与反爬应对。通过封装 API,可快速实现数据的复用与团队协作,同时通过请求频率控制、UA 伪装等措施降低被反爬风险。
后续可优化方向:
加入数据存储功能(如 MySQL、MongoDB),实现历史数据对比;
开发可视化界面(如 Vue+ECharts),直观展示商品价格、销量趋势;
完善代理 IP 池管理,支持大规模、分布式爬取(需严格控制频率)。
需再次强调:爬虫技术的使用需坚守法律与道德底线,仅针对公开数据,且不影响平台正常运营,共同维护健康的网络生态。