电商选品新逻辑:基于淘宝评论 API 的用户需求挖掘与爆款特征预测模型

在电商行业,"选品" 堪称运营的核心命脉。传统选品模式往往依赖经验判断、竞品模仿或平台推荐,这种方式不仅效率低下,还容易陷入 "同质化竞争" 的泥潭。随着电商 API 生态的成熟,基于用户评论数据的选品策略正在成为新趋势 —— 本文将详解如何通过淘宝评论 API 抓取用户反馈,结合 NLP 与机器学习技术挖掘需求痛点,并构建爆款特征预测模型,为电商选品提供数据驱动的新逻辑。
一、为什么淘宝评论数据是选品的 "金矿"?
用户评论是电商场景中最真实的需求载体。不同于商品标题、详情页等 "官方信息",评论内容包含:
显性需求:用户对产品功能、性能、价格的直接评价(如 "续航太差"、"尺寸偏小");
隐性需求:未被明确表达但可推断的潜在诉求(如频繁提及 "孩子用" 可能暗示 "儿童专用款" 需求);
情感倾向:对产品的满意度、吐槽点,直接反映市场接受度;
竞品对比:用户常提及 "比 XX 牌子好用",可挖掘差异化机会。
据统计,一款商品的评论数超过 1000 条时,其评论数据已能显著反映市场共性需求。而通过淘宝评论 API,我们可以批量获取多品类、多维度的评论数据,为选品决策提供量化依据。
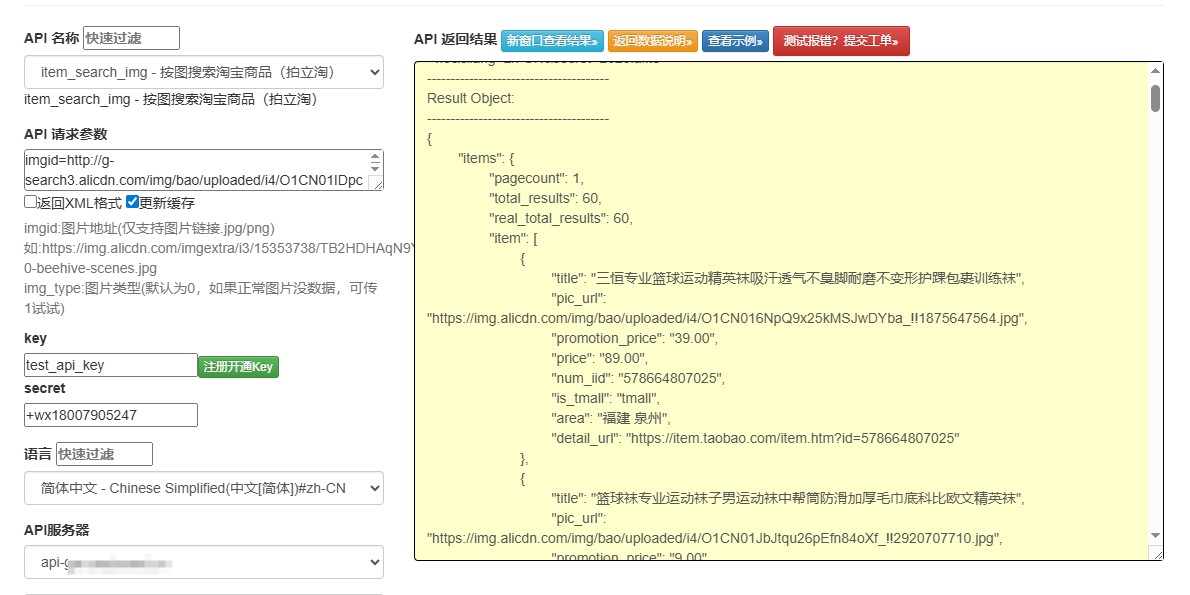
二、淘宝评论 API 接入与数据获取实战
1. API 接口选择与权限申请
淘宝开放平台(Open Platform)提供了两类评论相关 API:
商品评论列表接口(item_review):获取指定商品的评论列表,支持按时间、评分筛选;
评论分析接口(comment_analyze):返回评论的情感倾向、关键词标签等预处理结果。
接入前需完成开发者认证,注意接口调用的合规性:
单日调用量限制(普通开发者通常为 1000 次 / 天);
数据用途需符合《淘宝开放平台服务协议》,禁止商用转售;
需对抓取数据进行脱敏处理(如隐藏用户 ID、手机号)。
2. 数据获取代码示例(Python)
使用淘宝官方 SDK(top-api-sdk-python)调用接口,核心代码如下:
3. 数据存储与预处理
获取的评论数据需进行清洗,核心步骤包括:
去除重复评论(如同一用户重复刷屏);
过滤无效内容(如 "好评"、"不错" 等无意义短句);
统一格式(如将评分转为 1-5 分的数值型);
存储至数据库(推荐 MongoDB,适合存储非结构化文本)。
三、用户需求挖掘:从评论中提取 "可落地" 的信息
评论数据的价值在于 "从文字中挖需求",需结合自然语言处理(NLP)技术实现结构化分析。
1. 关键词提取与需求聚类
通过TF-IDF或TextRank算法提取高频关键词,识别用户关注的核心维度(如 "续航"、"材质"、"价格")。例如,对 1000 条耳机评论的关键词分析可能显示:
高频词:续航(320 次)、降噪(280 次)、佩戴舒适度(210 次);
可推断:用户对无线耳机的核心需求是 "长续航 + 强降噪"。
进一步通过K-Means 聚类将关键词分组,挖掘细分需求:
2. 情感分析与痛点识别
通过情感极性分析(正面 / 负面 / 中性)定位产品的 "口碑短板"。例如:
正面评论关键词:"音质好"、"物流快"(可强化的优势);
负面评论关键词:"容易断"、"客服差"(需规避的风险)。
推荐使用SnowNLP工具(适合中文情感分析):
3. 需求强度量化
通过 "关键词出现频率 + 情感得分" 构建需求强度矩阵,例如:
| 需求关键词 | 出现次数 | 正面情感占比 | 需求强度(次数 × 正面占比) |
|---|---|---|---|
| 长续航 | 320 | 0.85 | 272 |
| 降噪 | 280 | 0.72 | 201.6 |
| 低价 | 150 | 0.90 | 135 |
需求强度越高,说明该维度是用户的 "强诉求",可作为选品的核心指标。
四、爆款特征预测模型:从数据到选品决策
基于评论数据挖掘的需求特征,结合历史爆款商品的销售数据,可构建预测模型,判断一款商品成为 "爆款" 的概率。
1. 特征工程:定义 "爆款特征"
将评论数据转化为模型输入特征,包括:
需求匹配度:商品属性与高需求关键词的匹配程度(如 "长续航" 商品匹配度 = 1,否则 = 0);
负面评论率:负面评论占比(越低越好);
话题热度:评论中提及的新兴关键词(如 "电竞"、"轻量化")数量;
价格敏感度:评论中提及 "价格" 的频率(越高说明价格是关键决策因素)。
2. 模型选择与训练
推荐使用随机森林分类器(适合处理离散特征,抗过拟合能力强):
3. 模型应用:选品决策流程
初选:通过 API 获取目标品类 TOP100 商品的评论数据,计算需求强度矩阵;
筛选:保留需求匹配度 > 0.8、负面评论率 < 0.1 的商品;
预测:将筛选后的商品特征输入模型,选择预测爆款概率 > 0.7 的商品;
验证:结合供应链、成本等因素,最终确定 3-5 款候选商品。
五、落地价值与局限
1. 核心价值
降低试错成本:通过数据验证需求,减少 "凭感觉" 选品的风险;
挖掘细分机会:从评论中发现未被满足的小众需求(如 "大码女装 + 显瘦");
快速响应趋势:实时监控评论中的新兴关键词(如季节相关 "防晒"、"保暖")。
2. 局限性
API 依赖:接口调用限制可能影响数据量(可结合多平台 API 补充);
数据滞后性:评论数据反映的是历史需求,需结合实时热搜补充;
模型迭代:爆款特征随市场变化,需定期用新数据更新模型。
六、总结与展望
基于淘宝评论 API 的选品逻辑,本质是 "用用户声音指导决策"。从评论数据中挖掘需求、构建预测模型,不仅能提高选品成功率,更能帮助商家跳出同质化竞争,打造真正符合市场需求的差异化产品。
未来,随着大模型技术的发展,评论分析将向更细粒度(如用户画像匹配)、更实时化(如分钟级舆情监控)演进,电商选品也将进入 "数据驱动 + 智能预测" 的新阶段。
如果你正在做电商选品,不妨从调用第一个评论 API 开始,试试这套新逻辑吧!
欢迎在评论区交流:你在选品中遇到过哪些数据难题