API爬虫实战:淘宝页面数据抓取
在电商数据分析、竞品监控、供应链优化等场景中,淘宝平台的商品数据具有极高的商业价值。但淘宝作为国内头部电商平台,拥有严格的反爬机制与数据安全规范,非法爬虫不仅可能导致账号封禁,还可能触犯法律。因此,基于淘宝开放平台(TOP)官方 API 实现数据抓取,是兼顾合规性与稳定性的唯一正确路径。本文将从技术选型、平台接入、核心功能实现、风险控制四个维度,带你完成一次完整的淘宝 API 爬虫实战。
一、实战准备:资质与技术栈搭建
在开始编码前,需完成两项核心准备工作:获取官方 API 调用权限,以及搭建适配的技术环境。
1.1 淘宝开放平台资质申请
淘宝开放平台(Taobao Open Platform,TOP)仅对企业主体开放核心数据接口,个人开发者无法申请商品搜索、详情查询等关键权限,具体流程如下:
账号注册与企业认证:使用企业支付宝账号登录 TOP 平台,提交营业执照、法人信息完成认证(审核周期 1-3 个工作日);
创建应用:在 “开发者中心 - 应用管理” 中创建 “企业级应用”,选择应用类型为 “电商服务”,填写应用名称、用途(如 “竞品价格监控系统”);
申请接口权限:在 “接口管理” 中申请目标接口,核心推荐以下 3 个接口(覆盖商品搜索、详情、销量数据):
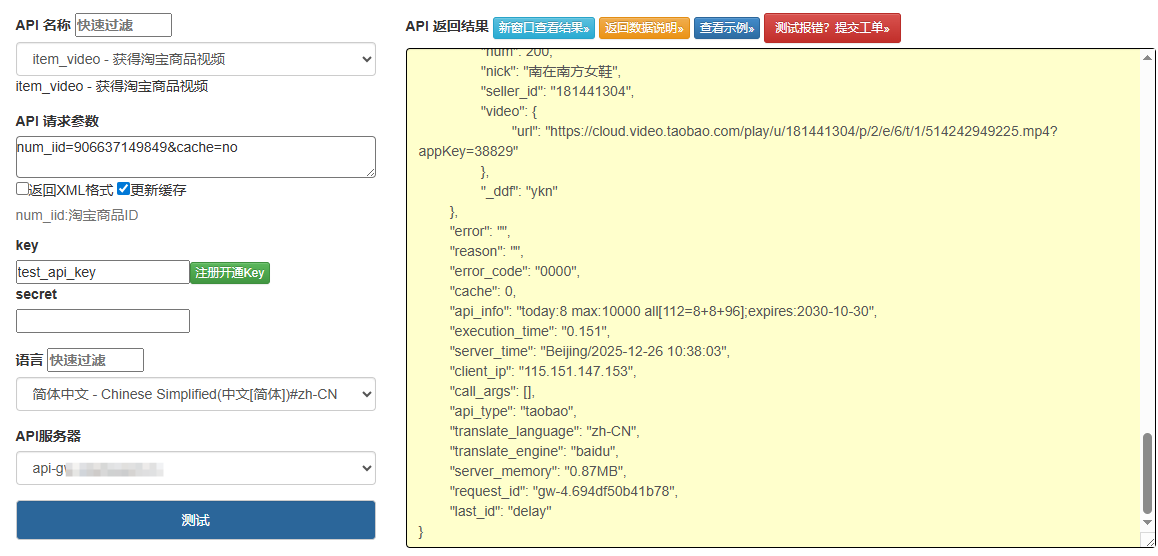
taobao.item.search:商品搜索接口(支持按关键词、价格、销量筛选);taobao.item.get:商品详情接口(获取标题、价格、SKU、库存等);taobao.soldquantity.get:商品销量接口(获取 30 天销量、成交记录);获取密钥:应用审核通过后,在 “应用详情” 中获取
App Key和App Secret(核心凭证,需妥善保管,避免泄露)。
1.2 技术栈选型
基于 “简单易用、生态完善” 原则,选择以下技术工具:
| 模块 | 工具 / 库 | 用途说明 |
|---|---|---|
| 编程语言 | Python 3.9+ | 开发效率高,HTTP 请求、JSON 解析库成熟 |
| HTTP 请求 | requests | 简洁的 HTTP 客户端,支持超时、代理配置 |
| 签名计算 | hashlib、hmac | 实现淘宝 API 要求的 HMAC-SHA1 签名机制 |
| 数据存储 | MongoDB | 存储非结构化商品数据(如 SKU 列表、规格参数) |
| 限流与重试 | tenacity、ratelimit | 控制 API 调用频率,处理临时失败 |
| 日志记录 | logging | 记录请求日志,便于问题排查 |
通过 pip 安装依赖库:
bash
二、核心原理:淘宝 API 签名机制
淘宝 API 采用 “参数签名” 验证请求合法性,任何未签名或签名错误的请求都会被直接拒绝。签名生成需遵循严格规则,核心步骤如下:
参数排序:将所有请求参数(含
app_key、method、timestamp等)按参数名 ASCII 码升序排列;拼接字符串:按 “参数名 = 参数值” 格式拼接排序后的参数,形成无分隔符的字符串;
生成签名:在拼接字符串前后分别添加
App Secret,使用 HMAC-SHA1 算法计算哈希值,再转为大写;添加签名:将生成的签名作为
sign参数加入请求,与其他参数一起发送。
示例代码(签名工具类):
python
运行
三、实战实现:商品数据抓取全流程
以 “按关键词抓取淘宝商品列表并存储” 为例,完整实现从请求发送、数据解析到存储的全流程。
3.1 步骤 1:商品搜索接口调用(taobao.item.search)
该接口支持按关键词、价格区间、销量排序等条件筛选商品,单次最多返回 40 条数据,需通过分页获取全量结果。
核心功能代码:
python
运行
3.2 步骤 2:数据解析与字段说明
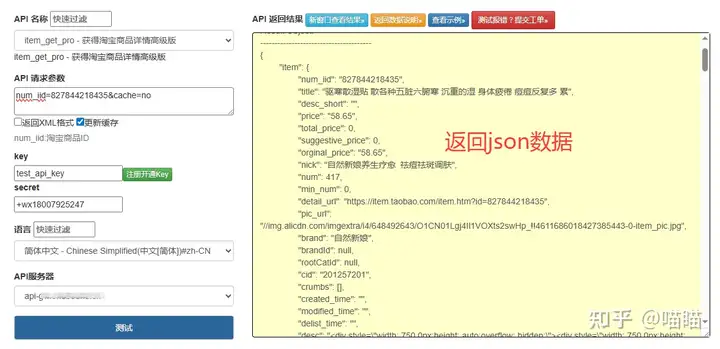
taobao.item.search接口返回的商品数据包含数十个字段,核心字段及解析说明如下:
| 字段名 | 类型 | 说明 | 示例值 |
|---|---|---|---|
num_iid |
字符串 | 商品唯一 ID(用于去重、详情查询) | "698765432109" |
title |
字符串 | 商品标题(含促销信息) | "秋季连衣裙女长袖显瘦" |
price |
字符串 | 商品价格(单位:元) | "129.90" |
sales |
整数 | 30 天销量 | 1256 |
nick |
字符串 | 卖家昵称 | "时尚女装店" |
shop_url |
字符串 | 店铺链接 | "" |
pic_url |
字符串 | 商品主图 URL | "" |
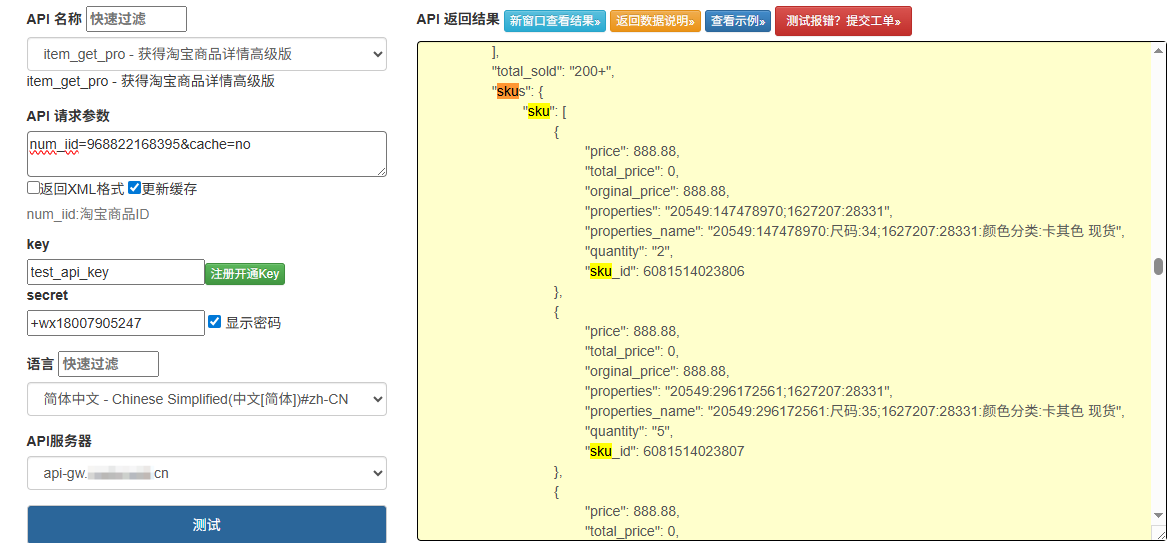
若需获取更详细的信息(如 SKU 规格、物流方式),可调用taobao.item.get接口,传入num_iid参数即可。
四、合规与风险控制:避免踩坑的关键
淘宝对 API 调用有严格的规范,任何违规操作都可能导致应用权限被冻结,需重点关注以下 3 点:
4.1 严格遵守调用限制
淘宝开放平台对不同等级的应用设置了不同的 QPS(每秒请求数)限制:
免费版应用:QPS=5(1 秒最多 5 次请求);
企业付费版:QPS=50-100(需申请升级)。
前文代码中已通过ratelimit库实现限流,若需更高 QPS,需通过淘宝开放平台提交 “业务场景说明” 申请升级,切勿通过多账号、多 IP 绕过限制(属于违规操作)。
4.2 数据使用合规
根据《淘宝开放平台服务协议》,抓取的数据仅可用于 “企业内部业务分析”,禁止以下行为:
将数据出售、转授权给第三方;
用于搭建竞品平台、比价工具(需单独申请专项权限);
存储用户隐私信息(如买家手机号、地址)。
建议在 MongoDB 中对敏感字段(如卖家联系方式)进行脱敏处理,避免合规风险。
4.3 异常处理与监控
错误码处理:淘宝 API 返回的常见错误码需针对性处理(如
110= 签名错误,403= 权限不足),可在send_taobao_request函数中添加错误码分支;监控告警:通过 Prometheus+Grafana 监控 API 调用成功率、响应时间,当失败率超过 5% 时触发邮件告警;
日志留存:将请求日志、错误日志留存至少 30 天,便于淘宝平台核查(若出现合规疑问)。
五、优化与进阶:从 “能用” 到 “好用”
基于基础版爬虫,可通过以下优化提升系统稳定性与实用性:
5.1 缓存策略:减少重复请求
对高频查询的商品数据(如热门商品详情),使用 Redis 缓存,缓存过期时间设为 1 小时(避免数据过时):
python
运行
5.2 分布式抓取:应对大量数据
当需要抓取数万条商品数据时,单进程效率较低,可通过 Celery 实现分布式任务调度:
将 “关键词 + 页码” 封装为任务,存入 RabbitMQ 消息队列;
多台服务器部署 Celery Worker,并行执行抓取任务;
用 MongoDB 实现任务状态跟踪(避免重复抓取)。
5.3 数据可视化:让数据产生价值
将抓取的商品数据通过 Matplotlib 或 FineBI 实现可视化分析,例如:
价格分布直方图:分析关键词 “秋季连衣裙” 的价格区间集中度;
销量 Top10 店铺排行:识别头部竞品商家;
价格波动曲线:监控特定商品的价格变化(需定时抓取)。
六、总结与展望
本文基于淘宝开放平台官方 API,实现了合规、稳定的商品数据抓取,核心要点可总结为:
合规优先:拒绝非法爬虫,通过企业认证获取官方接口权限;
签名必做:严格按照淘宝规范生成请求签名,避免请求被拒;
风险可控:通过限流、重试、监控保障系统稳定性,避免违规;
价值延伸:通过缓存、分布式、可视化提升数据利用效率。
后续可扩展的方向包括:集成淘宝联盟 API 实现佣金查询、对接供应链系统实现自动选品、结合 AI 模型预测商品销量趋势。但无论如何扩展,遵守平台规则与法律法规始终是爬虫项目的前提。

{kind=link}