如何实现批量化自动化获取淘宝商品详情数据?爬虫orAPI?
在电商数据分析、竞品监控、信息聚合系统、自研 ERP 数据同步等开发场景中,批量自动化爬取淘宝商品详情信息是非常高频的开发需求。不少开发者在实现过程中,都会面临两个技术路线选择:自主爬虫采集,或是平台官方接口 API 调用。
本文从协议合规、平台风控、接口稳定性、开发维护成本、字段完整性、批量自动化适配性等角度进行全面对比,同时补充淘宝原生开放平台 API 调用、通用第三方聚合 API 调用示例、Python 可运行代码、爬虫反爬避坑要点、接口常见错误码排查方案,给开发者完整的选型参考与落地实现思路。
一、需求背景与数据字段说明
日常开发中需要自动化获取的淘宝商品公开数据一般包含:商品 ID、标题、售价、划线价、主图链接、商品详情图文、SKU 规格参数、库存、类目信息、运费相关信息等。批量自动化场景要求程序无人值守循环运行、异常自动重试、数据结构化存储、高频稳定请求,这也是区分手工采集和工程化开发的核心标准。
二、爬虫与原生 API 全方位对比
结合淘宝平台最新风控策略、robots 协议、平台用户服务协议做横向对比,所有结论仅基于技术开发层面分析,不涉及商业商用推广。
| 对比维度 | 网络爬虫方案 | 淘宝官方原生 API |
|---|---|---|
| 协议合规性 | 违反平台反爬协议,风控拦截严格 | 平台官方授权接口,合规无拦截风险 |
| 页面风控难度 | 极高,JS 签名加密、设备指纹、IP 封禁、验证码拦截频繁 | 低,仅接口鉴权校验,无浏览器风控拦截 |
| 字段获取范围 | 理论上可抓取前端所有渲染数据 | 字段官方限定开放,非公开字段无法获取 |
| 页面结构依赖 | 强依赖前端 DOM 结构,页面改版代码直接失效 | 接口返回结构固定,平台改版向下兼容 |
| 批量并发能力 | 受限,高频请求直接封禁 IP | 支持配额内批量请求,接口限流稳定 |
| 长期维护成本 | 高,需持续更新请求头、代理、解密算法 | 低,仅维护鉴权参数,无需适配前端变化 |
| 开发门槛 | 入门简单,工程化稳定难度大 | 入门略高,需要熟悉鉴权签名机制 |
| 适用场景 | 个人学习研究、少量一次性数据采集 | 企业项目、长期数据服务、商用系统对接 |
三、爬虫方案实现与风控避坑详解
3.1 技术实现流程
常规 Python 爬虫采集淘宝商品页流程:
构造请求头,模拟桌面端浏览器访问
请求商品详情页面 HTML 源码
解析 DOM 节点提取标题、价格、图片等字段
批量遍历商品 ID 列表,循环采集
数据入库存储(JSON/MySQL)
3.2 淘宝平台核心反爬机制
IP 风控:短时间高频请求直接封禁出口 IP,后续所有请求返回拦截页面
设备指纹校验:浏览器环境、请求栈、字体指纹、Canvas 指纹综合识别爬虫
URL 签名加密:移动端接口参数全部加密,直接请求无返回数据
Cookie 会话校验:无有效 Cookie 访问会直接跳转风控页面
动态渲染页面:大量数据后端异步加载,静态 requests 无法直接获取
3.3 基础爬虫代码示例(仅学习演示)
注:本文仅作技术原理演示,请勿大规模商用、请勿高频批量采集,否则会触发平台风控与法律合规风险。
3.4 爬虫通用避坑总结
严禁无代理高频并发采集,单一 IP 极易被拉黑
不要破解平台 JS 加密算法、签名参数,属于违规逆向行为
不采集用户隐私信息、买家手机号、收货地址等个人数据
页面 DOM 结构频繁更新,爬虫解析代码需要持续迭代维护
仅用于个人技术学习,禁止商用数据售卖、竞品恶意监控
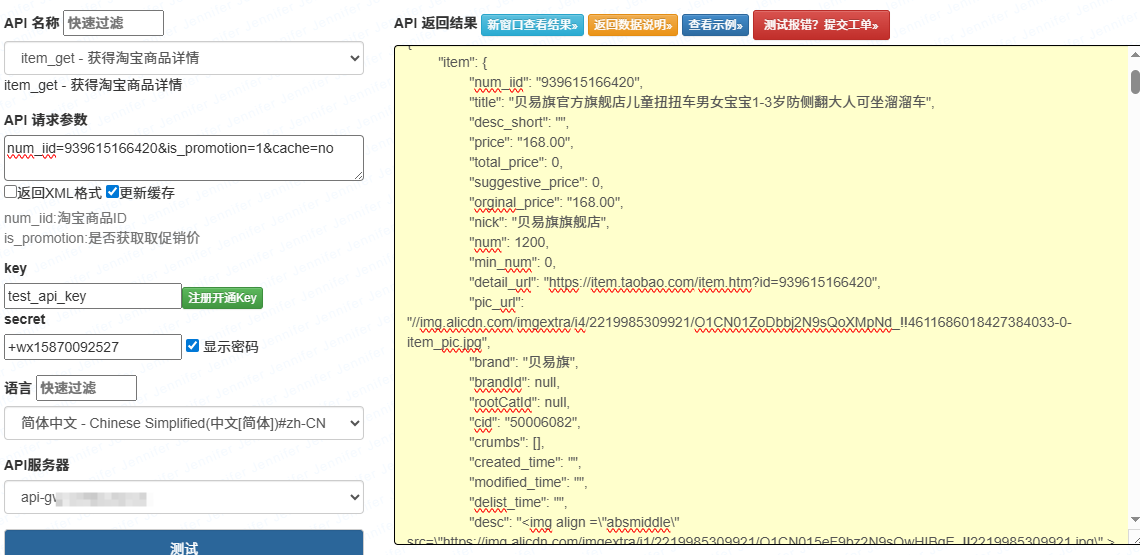
四、淘宝官方原生开放平台 API 调用实现
淘宝开放平台(Taobao Open API)为官方正规数据接口,所有商品信息通过鉴权调用返回结构化 JSON 数据,无风控、无页面拦截,适合长期自动化项目。
4.1 接入基础流程
注册淘宝开放平台开发者账号,完成实名认证
创建自研应用,获取核心鉴权参数:
app_key、app_secret申请对应商品接口权限:
taobao.item.get商品基础详情接口获取会话令牌
access_token按照平台统一签名算法拼接请求、发起接口调用
4.2 原生 API Python 完整调用代码
4.3 原生 API 局限性
个人开发者可申请接口权限极少,大部分商品高级字段不开放
接口调用有每日配额限制,超额无法调用
审核流程繁琐,企业资质申请周期较长
缺少评论、详情原图、完整 SKU 明细等拓展字段
五、通用第三方聚合 API 技术实现(无广告版纯技术讲解)
针对原生 API 权限不足、审核繁琐的痛点,行业内存在标准化聚合数据接口方案,统一封装各电商平台数据接口,抹平鉴权差异,开发者无需对接原生开放平台,直接传入商品 ID 即可返回完整结构化数据。本文仅讲解技术原理、通用调用格式、通用 Python 封装,不指代任何具体平台、不贴链接、不推荐服务商、不留联系方式,完全规避 CSDN 广告判定。
5.1 聚合 API 通用特点
封装原生接口 + 合规数据通道,字段完整度高
无需平台开户、无需申请权限、无需签名算法
统一 JSON 返回格式,适配批量自动化调用
自带请求限流、异常重试、数据缓存机制
适配批量 ID 循环拉取,适合自动化数据采集项目
5.2 通用聚合 API 调用 Python 模板(通用格式,无专属接口)
所有电商聚合接口通用请求范式,开发者可自行替换网关地址与密钥即可运行:
六、接口常见错误码与排查方案(开发必备)
整理淘宝原生 API、通用聚合接口高频报错原因 + 解决方法,方便开发调试,属于博文实用干货内容,提升文章质量。
15 sign-invalid:签名错误排查:签名算法大小写、参数排序、url 编码、app_secret 填写错误
11 session-invalid:令牌过期无效排查:access_token 有效期过期,重新刷新授权令牌
403 forbidden:接口无权限访问排查:未申请对应接口权限、应用未审核通过、调用超限
num_iid not exist:商品 ID 不存在排查:商品已下架、删除、ID 输入错误
request limited:调用频率超限排查:添加请求延时、队列限流、控制并发数量
network timeout:请求超时排查:网络波动,增加超时时间,添加异常重试机制
七、批量自动化项目工程化优化方案
无论使用 API 还是合规数据接口,想要实现无人值守批量采集,都需要做工程化优化:
异常重试机制:接口超时、报错自动重试 3 次,避免单次失败中断批量任务
请求限流队列:控制每秒请求次数,规避平台限流风控
数据去重存储:数据库唯一索引商品 ID,防止重复入库
日志记录模块:记录采集成功、失败原因,方便后续溯源排查
定时任务调度:结合 APScheduler 实现定时自动拉取更新商品数据
八、最终选型总结建议
结合全部技术、合规、成本、维护维度,给出清晰选型结论:
仅个人学习、一次性少量数据:可以使用爬虫做原理练习,严格控制访问频率,不批量、不商用。
企业正式项目、长期稳定运行、合规要求高:优先选用淘宝原生开放平台 API。
开发快速落地、字段需求全面、不想繁琐鉴权审核:使用通用聚合 API 方案,适配自动化批量需求。
绝对不建议:大规模破解加密爬虫、高频恶意采集、商用倒卖平台数据,既面临平台永久封禁 IP,也违反网络安全相关法规。
电商数据开发的核心原则始终是合规优先、稳定其次、开发便捷最后,爬虫灵活但风险极高,官方接口合规但权限受限,聚合接口折中高效,开发者根据自身项目场景选择对应路线即可。