电商平台公开数据采集实践:基于合规接口的数据分析方案

在电商行业数字化转型加速的当下,数据已成为企业优化运营、精准营销、提升竞争力的核心资产。电商平台公开数据(如商品基础信息、公开评价摘要、行业类目数据等)的采集与分析,能够帮助企业洞察市场趋势、了解竞品动态、优化产品布局。但需明确:数据采集的前提是合规,严禁爬取平台非公开数据、侵犯用户隐私或违反平台 robots 协议,本文将聚焦“合规接口”为核心的采集方案,结合实操案例,分享电商公开数据采集的全流程实践。
一、方案核心原则:合规优先,拒绝违规爬取
电商平台公开数据采集的核心底线的是“合规”,违规爬取(如突破平台反爬机制、采集未公开数据、高频恶意请求等)不仅可能导致IP被封禁、账号受限,还可能触犯《网络安全法》《数据安全法》等相关法律法规,承担法律责任。本方案严格遵循以下合规原则:
仅采集平台明确公开的非敏感数据,不涉及用户隐私(如手机号、地址)、商业机密(如未公开的销量、利润);
优先使用平台官方开放API、第三方合规数据接口,不使用爬虫程序破解平台反爬限制;
控制请求频率,遵循平台接口调用规范,不造成平台服务器负载压力;
采集的数据仅用于企业内部分析、市场调研,不用于非法传播、商业滥用。
二、合规接口选型:适配不同采集需求
电商公开数据采集的关键的是选择合规、稳定的接口,不同接口适配不同的采集场景,结合企业需求可分为三类,具体选型建议如下:
(一)平台官方开放API
主流电商平台(如淘宝、京东、拼多多等)均提供官方开放API,用于开发者合规获取平台公开数据,这是最安全、最稳定的采集方式。
适用场景:需要长期、批量采集某一平台的公开数据(如商品类目、公开评价、店铺基础信息等),适合企业级长期使用。
优势:合规性最高,数据准确性、稳定性强,接口更新有官方保障,无需担心反爬封禁;
注意事项:需完成平台开发者认证,部分API需申请开通权限,部分接口有调用次数限制(免费额度+付费升级),需严格遵循接口调用规范。
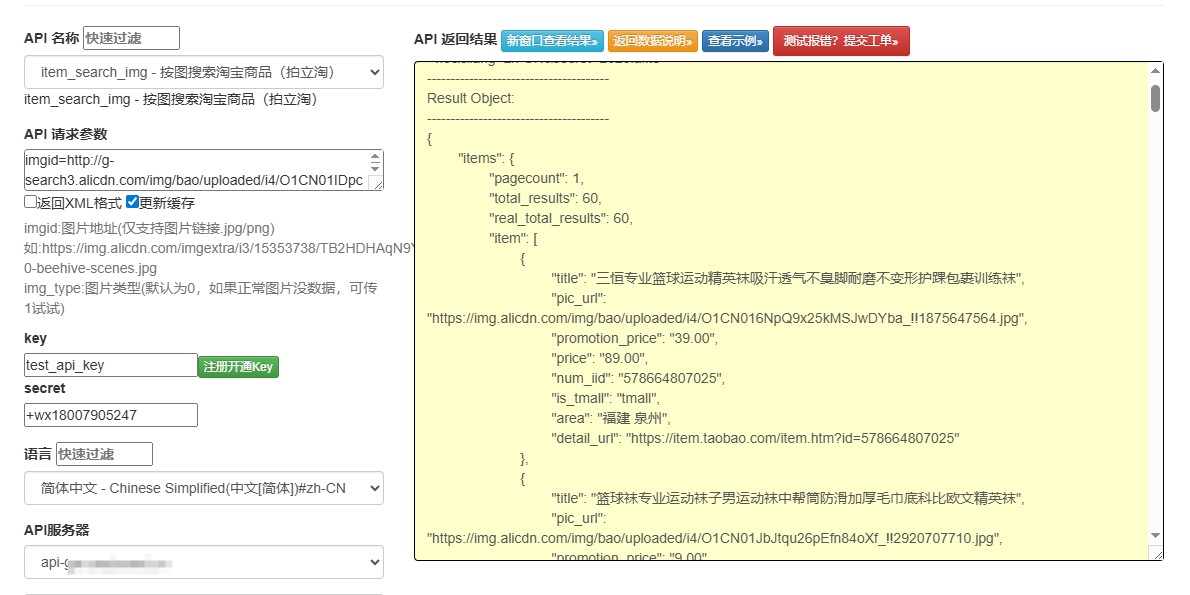
示例:淘宝开放平台的“商品搜索API”“店铺信息API”,可合规获取商品标题、价格、类目、店铺名称等公开信息。
(二)第三方合规数据接口
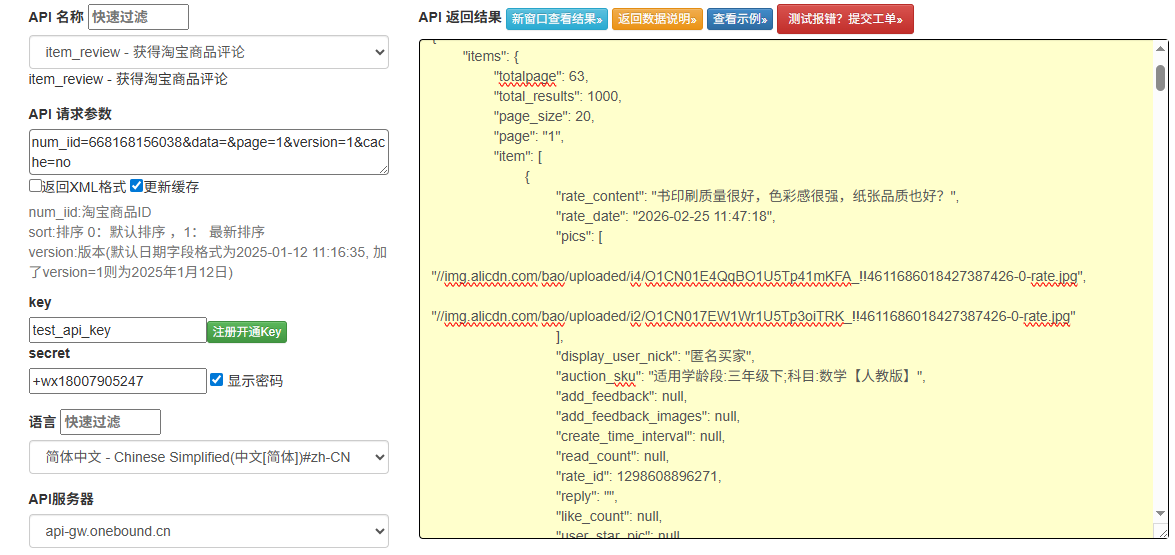
针对小型企业或个人开发者,若无需长期批量采集,或官方API权限申请复杂,可选择第三方合规数据服务提供商的接口(如万邦科技等)。
适用场景:短期采集、小批量数据获取,如临时的市场调研、竞品简单分析,无需投入过多精力对接官方API。
优势:接入门槛低,无需开发者认证,接口调用简单,支持多平台数据聚合(如同时采集淘宝、京东的公开商品数据);
注意事项:需选择有合法资质、口碑良好的第三方平台,确认其数据来源合规,避免使用来源不明的接口,同时注意控制调用成本。
(三)自定义合规采集接口(基于公开数据渲染)
对于部分未提供官方API、且第三方接口覆盖不全的场景,可基于平台公开页面的渲染数据,开发自定义合规采集接口,核心是“模拟正常用户访问,不破解、不侵入”。
适用场景:小众电商平台、特定场景的公开数据采集(如某平台的行业趋势公开数据),且需严格控制请求频率,模拟正常用户行为。
优势:灵活性高,可适配特殊采集需求;
注意事项:需严格遵循平台 robots 协议,不采集隐藏数据,不使用多IP代理、恶意请求等方式,避免触发平台反爬机制,建议添加请求间隔(如1-2秒/次)。
三、全流程采集实践:基于Python的合规接口调用案例
本文以“第三方合规接口”为例,结合Python语言,实现电商公开商品数据的采集、解析与存储,全程遵循合规原则,适合新手入门实践。
(一)环境准备
1. 开发环境:Python 3.8+,推荐使用PyCharm;
2. 核心依赖库:requests(接口请求)、pandas(数据处理)、json(数据解析)、mysql-connector-python(数据存储,可选);
3. 接口准备:在第三方合规数据平台(如聚合数据)申请“电商商品公开数据接口”,获取接口密钥(API Key),确认接口调用规范(请求频率、参数要求)。
(二)核心步骤:接口调用+数据解析+存储
1. 接口请求(合规控制)
核心是控制请求频率,携带合法参数,避免恶意请求。以下为示例代码(以聚合数据“电商商品搜索接口”为例):
import requests import time import pandas as pd # 第三方接口信息(替换为自己的API Key) API_KEY = "your_api_key" API_URL = "https://apis.juhe.cn/ecommerce/search" def get_ecommerce_data(keyword, page=1, page_size=10): """ 调用第三方合规接口,获取电商公开商品数据 :param keyword: 搜索关键词(如“儿童玩具”) :param page: 分页页码 :param page_size: 每页数据量 :return: 解析后的商品数据列表 """ # 接口请求参数(遵循接口规范) params = { "key": API_KEY, "keyword": keyword, "page": page, "page_size": page_size, "platform": "taobao" # 可指定平台(淘宝、京东等) } try: # 发送请求,控制请求间隔(1秒/次,避免高频请求) time.sleep(1) response = requests.get(API_URL, params=params, timeout=10) response.raise_for_status() # 抛出请求异常(如404、500) data = response.json() # 接口返回校验(确认请求成功) if data["error_code"] == 0: return data["result"]["items"] # 返回商品数据列表 else: print(f"接口请求失败:{data['reason']}") return [] except Exception as e: print(f"请求异常:{str(e)}") return []
2. 数据解析(提取有效信息)
接口返回的数据多为JSON格式,需提取核心有效信息(如商品标题、价格、店铺名称、类目等),过滤无效数据,确保数据完整性。示例代码:
def parse_data(items): """ 解析商品数据,提取核心信息 :param items: 接口返回的商品数据列表 :return: 结构化数据列表 """ parsed_data = [] for item in items: # 提取公开的核心信息(不涉及敏感数据) product_info = { "商品标题": item.get("title", ""), "商品价格": item.get("price", 0.0), "店铺名称": item.get("shop_name", ""), "商品类目": item.get("category", ""), "公开评价数": item.get("comment_count", 0), "采集时间": time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()) } # 过滤无效数据(如价格为0、标题为空的商品) if product_info["商品标题"] and product_info["商品价格"] > 0: parsed_data.append(product_info) return parsed_data
3. 数据存储(持久化管理)
将解析后的结构化数据存储到本地文件(CSV)或数据库(MySQL),方便后续分析使用。示例代码(存储为CSV文件):
def save_data(parsed_data, save_path="ecommerce_data.csv"): """ 将解析后的数据存储为CSV文件 :param parsed_data: 结构化数据列表 :param save_path: 存储路径 """ if not parsed_data: print("无有效数据可存储") return # 转换为DataFrame,便于存储和后续分析 df = pd.DataFrame(parsed_data) # 追加存储(避免覆盖已有数据) df.to_csv(save_path, mode="a", index=False, header=not pd.io.common.file_exists(save_path), encoding="utf-8-sig") print(f"数据存储成功,共存储{len(parsed_data)}条商品数据") # 主函数:执行采集流程 if __name__ == "__main__": # 采集关键词(可根据需求修改) keywords = ["儿童玩具", "小学生文具"] # 分页采集(避免单页请求过多数据) for keyword in keywords: print(f"开始采集关键词:{keyword}") for page in range(1, 3): # 采集1-2页数据 items = get_ecommerce_data(keyword, page=page, page_size=10) parsed_data = parse_data(items) save_data(parsed_data) print("采集完成,数据已存储至ecommerce_data.csv")
四、数据清洗与数据分析应用
采集到的公开数据可能存在重复、缺失、异常等问题,需先进行清洗,再用于实际分析,以下为核心步骤:
(一)数据清洗
1. 去重:删除重复的商品数据(如同一商品ID重复采集);
2. 补全:对缺失的非关键字段(如类目)进行填充,关键字段(如标题、价格)缺失的数据直接删除;
3. 去异常:删除价格异常(如远低于市场价、远高于市场价)、评价数异常的数据;
4. 标准化:统一数据格式(如价格保留2位小数、类目统一命名)。
(二)数据分析应用场景
基于合规采集的公开数据,可实现以下核心应用,为电商运营提供决策支持:
市场趋势分析:通过采集不同时间段的商品价格、类目分布数据,分析市场需求变化(如某类商品价格走势、热门类目占比);
竞品分析:采集竞品商品的价格、评价、类目等数据,对比自身产品的优势与不足,优化产品定价和布局;
用户偏好分析:通过公开评价摘要(非隐私信息),提取用户对商品的核心需求和反馈,优化产品功能;
类目优化:分析不同类目的商品销量、评价情况,调整店铺类目布局,聚焦高需求、高好评的类目。
五、合规采集避坑指南
在电商公开数据采集过程中,容易出现合规风险和技术问题,结合实践经验,总结以下避坑要点:
拒绝“破解反爬”:不使用爬虫框架(如Scrapy)破解平台反爬机制,不使用代理IP批量请求、不伪造用户身份,避免IP封禁和法律风险;
严格控制请求频率:无论使用官方API还是第三方接口,均需遵循接口调用规范,避免高频请求给平台服务器造成压力,建议设置1-2秒/次的请求间隔;
明确数据用途:采集的数据仅用于企业内部分析、市场调研,不用于商业竞争、非法传播,不泄露采集到的公开数据;
定期检查接口状态:官方API和第三方接口可能会更新、调整,需定期检查接口调用情况,及时适配接口变化,避免采集失败;
规避敏感数据:严禁采集用户隐私(如手机号、收货地址、身份证号)、平台商业机密(如未公开的销量、利润、后台数据),仅采集页面公开的非敏感信息。
六、方案总结
电商平台公开数据采集的核心是“合规”,基于官方开放API、第三方合规接口的采集方案,既能够保证数据的准确性、稳定性,又能规避法律风险和技术风险。本文通过实操案例,完整展示了从接口选型、环境搭建、接口调用、数据解析、存储到数据分析的全流程,适合企业和开发者用于合规的市场调研、运营优化。
后续可根据实际需求,优化采集策略(如增加多平台数据采集、定时自动采集),深化数据分析(如结合可视化工具Tableau、Matplotlib实现数据可视化),让公开数据真正为电商运营赋能。同时,需始终坚守合规底线,随着数据监管政策的完善,持续优化采集方案,确保数据采集与使用的合法性、合规性。