电商商品数据抓取技术实战:从环境搭建到数据落地全流程
一、实战前置:环境搭建与工具选型
1.1 基础环境搭建
下载Python安装包(官网选择3.8+版本),勾选“Add Python to PATH”,完成安装后,终端输入
python --version验证是否成功。安装核心依赖库,终端执行以下命令(涵盖请求、解析、动态渲染、数据保存等全场景):
pip install requests # 发送HTTP请求(核心工具)pip install beautifulsoup4 # 解析静态HTML页面pip install lxml # 解析XML/HTML(比bs4更高效)pip install selenium # 模拟浏览器行为(应对动态渲染)pip install webdriver-manager # 自动管理浏览器驱动(无需手动下载)pip install pandas # 数据清洗与保存(导出Excel/Csv)pip install fake-useragent # 生成随机UA(应对基础反爬)pip install proxy_pool # 简单代理池(应对IP封禁)
1.2 工具选型核心逻辑
页面类型 | 核心特征 | 工具组合 | 适用场景 |
|---|---|---|---|
静态页面 | 页面源码包含所有商品数据,F12查看源码可直接找到目标内容 | requests + beautifulsoup4/lxml | 小型电商平台、商品详情页(无动态加载) |
动态页面 | 商品数据通过JS加载,源码中无目标内容,滚动页面才加载 | selenium + webdriver-manager / Scrapy + Splash | 主流电商平台(淘宝、京东、拼多多)商品列表、详情页 |
接口返回 | F12网络面板可找到商品数据接口(JSON格式) | requests + json | 所有平台(最优方案,效率高于页面解析) |
二、核心技术拆解:从请求到解析全流程
2.1 第一步:确定目标数据与分析页面
- 目标数据(以电商商品为例,通用字段):
基础信息:商品标题、商品ID、售价、原价、库存、销量
详情信息:商品描述、规格参数、图片链接
关联信息:店铺名称、店铺评分、用户评价数量
- 页面分析方法(以Chrome浏览器为例):
查看静态源码:打开目标页面→右键“查看页面源代码”→Ctrl+F搜索目标关键词(如商品标题),若能找到,说明是静态页面;若找不到,说明是动态页面/接口返回。
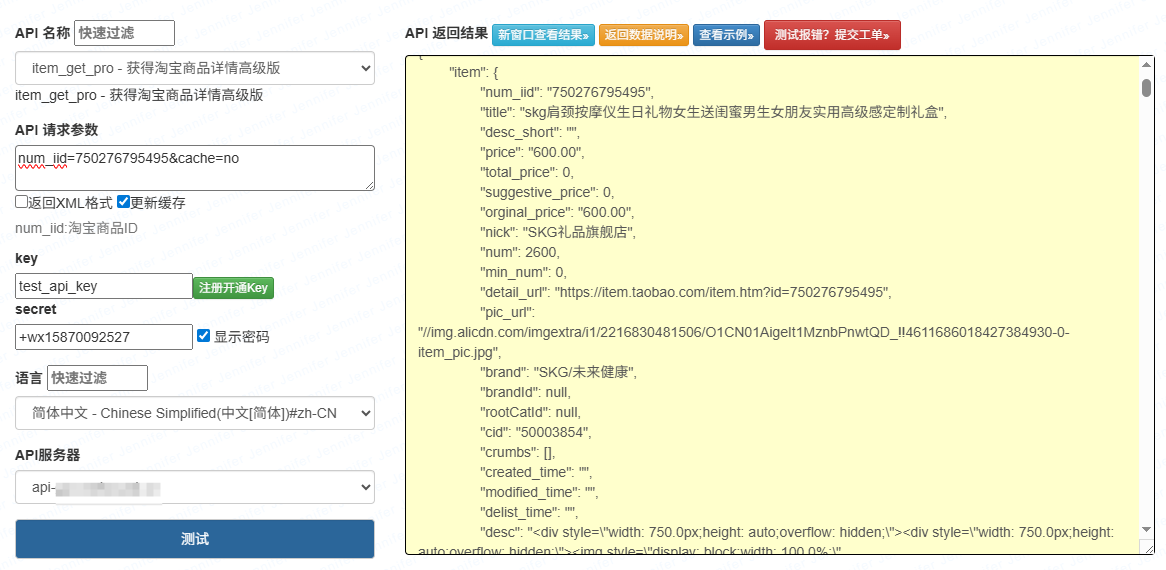
查看网络接口:打开目标页面→F12打开开发者工具→切换到“网络”面板→刷新页面→筛选“XHR/JS”类型,查看请求URL,点击“响应”查看是否有JSON格式的商品数据(重点关注含“product”“goods”“list”等关键词的接口)。
2.2 第二步:模拟请求获取资源(核心避坑点)
2.2.1 静态页面请求(requests)
import requests
from fake_useragent import UserAgent
from bs4 import BeautifulSoup
# 1. 伪装请求头(关键:UA随机切换,Cookie可选,根据目标网站要求添加)
ua = UserAgent()
headers = {
"User-Agent": ua.random, # 随机生成UA,避免固定UA被封禁
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Referer": "https://www.target.com/", # Referer,模拟从目标网站跳转
# "Cookie": "xxx", # 若需要登录/验证,可从浏览器复制Cookie
}
# 2. 发送请求(try-except捕获异常,避免请求失败导致程序崩溃)
try:
# 目标页面URL(以某电商商品列表为例)
url = "https://www.target.com/goods/list?category=123"
# 发送GET请求,timeout设置超时时间(避免无限等待)
response = requests.get(url, headers=headers, timeout=10)
# 验证请求是否成功(状态码200为成功)
response.raise_for_status()
# 设置编码,避免中文乱码
response.encoding = response.apparent_encoding
# 获取页面源码
html = response.text
print("请求成功,页面源码长度:", len(html))
except Exception as e:
print("请求失败,异常信息:", str(e))2.2.2 动态页面请求(Selenium)
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
import time
# 1. 初始化浏览器(无头模式,不弹出浏览器窗口,适合服务器运行)
options = webdriver.ChromeOptions()
options.add_argument("--headless=new") # 无头模式
options.add_argument("--disable-gpu") # 禁用GPU,避免报错
options.add_argument(f"user-agent={ua.random}") # 随机UA
# 自动管理Chrome驱动,无需手动下载
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
try:
# 2. 访问目标页面
url = "https://www.target.com/goods/list?category=123"
driver.get(url)
# 模拟滚动页面(动态加载需要滚动才能加载更多商品)
# 滚动到页面底部,执行3次(根据页面加载规则调整次数)
for i in range(3):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # 等待2秒,给JS加载时间(避免加载不完整)
# 3. 获取加载后的完整页面源码
html = driver.page_source
print("动态页面加载成功,源码长度:", len(html))
# 可选:直接通过Selenium定位元素获取数据(无需解析源码)
# 定位商品标题(根据页面元素XPath定位,需在浏览器F12中复制)
titles = driver.find_elements(By.XPATH, '//div[@class="goods-title"]')
for title in titles:
print("商品标题:", title.text.strip())
except Exception as e:
print("动态页面请求失败,异常信息:", str(e))
finally:
# 关闭浏览器,避免占用资源
driver.quit()2.2.3 接口请求(最优方案)
import requests
import json
from fake_useragent import UserAgent
ua = UserAgent()
headers = {
"User-Agent": ua.random,
"Accept": "application/json, text/plain, */*",
"Referer": "https://www.target.com/",
}
try:
# 目标接口URL(从浏览器网络面板复制,替换动态参数)
# 示例:页码page=1,分类category=123
api_url = "https://www.target.com/api/goods/list?page=1&category=123"
response = requests.get(api_url, headers=headers, timeout=10)
response.raise_for_status()
# 解析JSON数据
data = response.json()
print("接口请求成功,返回数据:", json.dumps(data, ensure_ascii=False, indent=2))
# 提取商品列表数据(根据接口返回结构调整键名)
goods_list = data.get("data", {}).get("goodsList", [])
for goods in goods_list:
goods_id = goods.get("id")
title = goods.get("title")
price = goods.get("price")
sales = goods.get("sales")
print(f"商品ID:{goods_id},标题:{title},价格:{price},销量:{sales}")
except Exception as e:
print("接口请求失败,异常信息:", str(e))2.3 第三步:解析数据(提取目标字段)
3.1 静态/动态页面解析(BeautifulSoup+lxml)
from bs4 import BeautifulSoup
# 假设已获取页面源码html(来自requests或Selenium)
soup = BeautifulSoup(html, "lxml") # 指定lxml解析器,效率更高
# 解析商品列表(根据页面元素结构调整,需在浏览器F12中查看)
goods_items = soup.find_all("div", class_="goods-item") # 找到所有商品项
for item in goods_items:
# 1. 商品标题(text获取文本,strip()去除空格)
title = item.find("a", class_="goods-title").text.strip() if item.find("a", class_="goods-title") else "未知"
# 2. 商品价格(获取标签内的文本,处理价格格式)
price = item.find("span", class_="goods-price").text.strip().replace("¥", "") if item.find("span", class_="goods-price") else "0"
# 3. 商品图片链接(获取img标签的src属性)
img_url = item.find("img", class_="goods-img")["src"] if item.find("img", class_="goods-img") else ""
# 4. 销量(处理可能的空值)
sales = item.find("span", class_="goods-sales").text.strip().replace("销量:", "") if item.find("span", class_="goods-sales") else "0"
# 打印解析结果
print(f"标题:{title},价格:{price}元,销量:{sales},图片链接:{img_url}")3.2 接口数据解析(JSON)
import json
# 假设已获取接口返回的JSON字符串(response.text)
data = json.loads(response.text)
# 提取核心字段(根据接口返回结构调整,以下为通用示例)
# 1. 分页信息(判断是否有下一页,用于多页抓取)
total_page = data.get("data", {}).get("totalPage", 1)
current_page = data.get("data", {}).get("currentPage", 1)
# 2. 商品列表数据
goods_list = data.get("data", {}).get("goodsList", [])
parsed_data = [] # 用于存储解析后的结构化数据
for goods in goods_list:
parsed_goods = {
"goods_id": goods.get("id", ""), # 商品ID
"title": goods.get("title", "未知"), # 标题
"original_price": goods.get("originalPrice", 0), # 原价
"current_price": goods.get("currentPrice", 0), # 现价
"sales": goods.get("sales", 0), # 销量
"stock": goods.get("stock", 0), # 库存
"shop_name": goods.get("shop", {}).get("name", "未知"), # 店铺名称
"img_url": goods.get("imgUrl", ""), # 图片链接
"create_time": goods.get("createTime", "") # 上架时间
}
parsed_data.append(parsed_goods)
# 打印解析后的结构化数据
print("解析完成,共提取商品:", len(parsed_data))
for goods in parsed_data[:3]: # 打印前3条
print(goods)2.4 第四步:保存数据(落地可用)
import pandas as pd
# 假设已获取解析后的结构化数据parsed_data(列表嵌套字典)
# 1. 保存为Excel文件(最常用,易查看)
df = pd.DataFrame(parsed_data)
# 保存Excel,index=False不保存行索引,encoding避免中文乱码
df.to_excel("电商商品数据.xlsx", index=False, encoding="utf-8-sig")
print("Excel文件保存成功!")
# 2. 保存为CSV文件(适合大数据量,占用空间小)
df.to_csv("电商商品数据.csv", index=False, encoding="utf-8-sig")
print("CSV文件保存成功!")
# 3. 保存为JSON文件(适合后续程序调用)
with open("电商商品数据.json", "w", encoding="utf-8") as f:
json.dump(parsed_data, f, ensure_ascii=False, indent=2)
print("JSON文件保存成功!")三、实战案例:抓取某电商平台商品列表(完整可运行)
3.1 案例需求
抓取目标:某电商平台手机品类商品列表(前3页)
抓取字段:商品ID、标题、现价、原价、销量、店铺名称、图片链接
技术选型:Selenium(动态页面)+ BeautifulSoup(解析)+ pandas(保存)
3.2 完整代码
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
import pandas as pd
import time
from fake_useragent import UserAgent
# 初始化参数
target_url = "https://www.target.com/category/phone" # 目标电商手机品类URL
page_count = 3 # 抓取前3页
parsed_data = [] # 存储解析后的商品数据
ua = UserAgent()
# 初始化浏览器(无头模式)
def init_browser():
options = webdriver.ChromeOptions()
options.add_argument("--headless=new")
options.add_argument("--disable-gpu")
options.add_argument(f"user-agent={ua.random}")
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
return driver
# 抓取单页数据
def crawl_single_page(driver, url):
try:
driver.get(url)
# 模拟滚动页面,加载完整商品数据
time.sleep(3) # 等待页面初始加载
for i in range(2):
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
# 获取页面源码,解析数据
html = driver.page_source
soup = BeautifulSoup(html, "lxml")
goods_items = soup.find_all("div", class_="goods-item") # 替换为目标页面的商品项类名
for item in goods_items:
# 提取目标字段(替换为目标页面的元素定位规则)
goods_id = item.get("data-id", "") if item.get("data-id") else ""
title = item.find("a", class_="goods-title").text.strip() if item.find("a", class_="goods-title") else "未知"
current_price = item.find("span", class_="current-price").text.strip().replace("¥", "") if item.find("span", class_="current-price") else "0"
original_price = item.find("span", class_="original-price").text.strip().replace("¥", "") if item.find("span", class_="original-price") else current_price
sales = item.find("span", class_="sales-count").text.strip().replace("销量:", "") if item.find("span", class_="sales-count") else "0"
shop_name = item.find("div", class_="shop-name").text.strip() if item.find("div", class_="shop-name") else "未知"
img_url = item.find("img", class_="goods-img")["src"] if item.find("img", class_="goods-img") else ""
# 存储结构化数据
parsed_goods = {
"商品ID": goods_id,
"商品标题": title,
"现价(元)": current_price,
"原价(元)": original_price,
"销量": sales,
"店铺名称": shop_name,
"图片链接": img_url
}
parsed_data.append(parsed_goods)
print(f"当前页面抓取完成,共提取商品:{len(goods_items)}条")
except Exception as e:
print(f"单页抓取失败,异常信息:{str(e)}")
# 多页抓取(根据目标页面的分页规则调整URL)
def crawl_multi_page(driver, base_url, page_count):
for page in range(1, page_count + 1):
print(f"\n开始抓取第{page}页...")
# 替换分页参数(根据目标页面的分页URL规则调整,如page=1、p=1)
page_url = f"{base_url}?page={page}"
crawl_single_page(driver, page_url)
# 控制请求频率,避免过快被反爬
if page != page_count:
time.sleep(5)
# 保存数据
def save_data(data, filename):
df = pd.DataFrame(data)
df.to_excel(f"{filename}.xlsx", index=False, encoding="utf-8-sig")
df.to_csv(f"{filename}.csv", index=False, encoding="utf-8-sig")
print(f"\n数据保存成功!生成文件:{filename}.xlsx 和 {filename}.csv")
# 主函数(程序入口)
if __name__ == "__main__":
print("="*50)
print("开始电商商品数据抓取...")
print("="*50)
# 初始化浏览器
driver = init_browser()
try:
# 多页抓取
crawl_multi_page(driver, target_url, page_count)
# 保存数据
if parsed_data:
save_data(parsed_data, "电商手机品类商品数据")
print(f"\n抓取完成!共抓取商品:{len(parsed_data)}条")
else:
print("\n未抓取到任何商品数据,请检查页面定位规则或反爬设置!")
finally:
# 关闭浏览器
driver.quit()
print("\n浏览器已关闭,程序结束!")3.3 案例注意事项
替换定位规则:代码中的“goods-item”“current-price”等类名,需根据目标电商平台的页面元素调整(在Chrome F12中复制元素的类名/XPath)。
调整分页URL:不同平台的分页参数不同(如京东是“page=1”,淘宝是“s=1”),需根据目标页面的分页URL规则修改page_url的拼接逻辑。
控制请求频率:time.sleep()的时间可根据平台反爬严格程度调整(反爬严则延长至3-5秒),避免过快请求导致IP封禁。
四、实战避坑:反爬应对与常见问题解决
4.1 坑点1:请求被拒绝(403 Forbidden)
4.2 坑点2:动态页面抓取不到数据
4.3 坑点3:IP被封禁(无法访问目标网站)
4.4 坑点4:数据解析为空(解析不到目标字段)
4.5 坑点5:程序崩溃(请求超时、元素不存在)
五、技术优化:提升抓取效率与稳定性
5.1 效率优化
多线程/多进程抓取:使用threading(多线程)或multiprocessing(多进程),同时抓取多个页面,提升抓取速度(注意:控制线程/进程数量,避免请求过快被反爬)。
优先使用接口:接口抓取效率远高于页面解析,尽可能分析目标平台的接口,减少页面渲染和解析的耗时。
批量保存数据:避免每抓取1条数据就保存1次,先存储在内存中,抓取完成后批量保存,减少IO操作耗时。
5.2 稳定性优化
搭建代理池:使用proxy_pool+Redis搭建稳定的代理池,自动筛选可用代理,避免IP封禁。
添加重试机制:请求失败时,自动重试(设置重试次数,如3次),避免网络波动导致的抓取失败。
日志记录:使用logging模块记录抓取过程(请求成功/失败、异常信息、抓取数量),便于排查问题。
断点续爬:将已抓取的页面/商品ID保存到文件,程序中断后,重新运行时可跳过已抓取内容,避免重复抓取。
5.3 合规优化
遵守robots协议:查看目标平台的robots.txt文件(如https://www.target.com/robots.txt),不抓取协议禁止的内容。
控制抓取频率:避免过度抓取,给平台服务器造成压力,否则可能面临法律追责。
数据用途合规:抓取的数据仅用于个人学习、市场分析,不得用于商业侵权、恶意竞争等非法用途。
六、总结与延伸
工具选型:优先接口>静态页面(requests)>动态页面(Selenium),根据页面类型灵活选择。
核心避坑:完善请求头、控制请求频率、使用代理IP、处理空值和异常,是抓取成功的关键。
实战核心:先分析页面/接口,再模拟请求,最后解析保存,一步一步落地,避免跳步导致的问题。