电商数据对接卡壳?淘宝商品详情 API 核心要点梳理

在电商数据开发、竞品分析系统搭建、电商 BI 平台对接等场景中,淘宝商品详情 API 是获取核心数据的重要通道,但多数开发者在实际对接过程中,常会卡在签名生成、参数构造、数据解析、异常处理等关键环节,甚至因忽略细节导致接口调用失败、数据返回异常,反复调试却效率极低。
本文从技术实操视角,针对淘宝商品详情 API 对接过程中最易卡壳的环节,梳理从前置准备、调用开发、数据解析到生产落地的全流程核心要点,同时总结高频问题的解决思路,以及服务商选型的关键标准,帮开发者一站式解决对接卡壳问题,实现 API 的高效、稳定对接,内容均为实战总结的纯技术干货,适用于 Python、Java、PHP 等所有主流开发语言的开发者。
一、对接前核心准备要点:打好基础,避免起步卡壳
多数对接卡壳问题并非出在开发环节,而是前置准备不充分,比如凭证管理不当、接口规则理解模糊、测试工具未到位,这部分是对接的基础,需做到 “三个确认、一个准备”,从源头规避问题。
1.1 核心凭证确认与管理
正规淘宝商品详情 API 服务商都会提供AppKey(应用密钥)、AppSecret(签名密钥)、接口请求地址三大核心凭证,这是对接的基础,需注意两个要点:
凭证需单独存储,禁止硬编码到业务代码中(尤其生产环境),避免代码泄露导致凭证被盗用;
确认凭证的有效性,测试前先通过服务商提供的测试接口验证,避免使用过期 / 无效凭证导致后续调试无意义。
1.2 接口规则核心确认
对接前必须逐字确认服务商的接口文档,重点明确4 个核心规则,这是避免调用卡壳的关键,也是新手最易忽略的点:
请求方式:行业主流为 GET,部分服务商支持 POST,需严格匹配,不可随意更改;
签名规则:明确签名的字符串拼接顺序(如 AppKey+ItemId+AppSecret)、加密算法(MD5 为行业通用,部分为 HMAC-SHA256)、大小写要求(多为加密后转大写);
参数编码:确认是否需要对请求参数做UTF-8 URL 编码,尤其参数中包含特殊字符(如 &、=、空格)时,编码不规范会导致参数传递失败;
调用限制:明确单条 / 批量调用的 ID 数量限制、单账号调用频率限制(如 QPS=10、分钟调用量 = 1000),避免后续批量开发时超出限制。
1.3 开发与测试环境准备
测试工具:优先使用Postman、Apifox等可视化接口调试工具,零代码完成单条接口测试,确认凭证、规则、参数无误后,再进行代码开发,大幅减少调试成本;
开发库准备:根据开发语言安装对应的网络请求库与加密库,如 Python 的
requests+hashlib、Java 的OkHttp+commons-codec、PHP 的curl+md5,均为原生 / 轻量库,无需额外封装;环境隔离:测试环境与生产环境使用不同的 AppKey,避免测试过程中占用生产环境的调用额度,或因测试操作影响生产环境。
二、接口调用核心技术要点:直击关键,解决开发卡壳
接口调用是对接过程中卡壳率最高的环节,核心问题集中在签名生成、参数构造两大模块,本部分梳理这两个核心模块的实操要点,同时给出通用的调用开发规范,适用于所有语言的开发落地。
2.1 签名生成:核心中的核心,规避 90% 的调用失败
签名验证失败是对接中最常见的问题,本质是未严格遵循服务商的签名规则,总结签名生成的4 个硬性要点,按此执行可彻底解决签名卡壳问题:
拼接顺序不可改:严格按服务商文档的顺序拼接字符串(如 AppKey→ItemId→AppSecret),多一个字符、少一个字符、顺序颠倒,都会导致签名无效;
编码统一为 UTF-8:拼接后的字符串需按UTF-8编码后再加密,避免因编码格式(如 GBK)不一致导致加密结果错误;
无冗余字符:拼接字符串时禁止添加空格、换行、分隔符,即使是注释性字符也会导致签名失败;
加密后大小写匹配:按文档要求将加密结果转大写 / 小写,行业主流为大写,无需额外做其他处理。
通用签名生成伪代码(适配 MD5 加密,多语言可直接套用逻辑):
plaintext
2.2 参数构造:规范构造,避免参数传递卡壳
参数构造的核心是 **“必传必带、可选按需、编码规范”**,新手常因参数缺失、编码不规范导致数据返回异常,梳理核心要点:
必传参数完整:核心必传参数为
app_key、item_id、sign,无特殊要求无需额外添加其他参数,避免画蛇添足;item_id 格式正确:单条调用传字符串类型的单个 ID,批量调用传ID 数组(如 [123456,789012]),部分服务商要求批量 ID 用英文逗号分隔(如 "123456,789012"),按文档要求调整;
URL 编码规范:对所有请求参数的值做 URL 编码,尤其当商品标题中包含特殊字符,或批量 ID 中有分隔符时,编码后可避免参数被截断;
可选参数按需添加:如
format(返回格式,默认 JSON)、fields(指定返回字段),无需时可不传,减少参数冗余。
2.3 请求发送:标准化开发,避免请求环节卡壳
请求发送的逻辑较为简单,核心是匹配请求方式、设置合理超时、捕获请求异常,梳理 3 个实操要点:
严格匹配请求方式:文档指定 GET 则用 GET,指定 POST 则用 POST,POST 请求需注意将参数放在请求体中,且设置请求头
Content-Type: application/x-www-form-urlencoded;设置合理超时时间:建议设置10-30s的超时时间,避免因网络波动导致请求挂起,占用服务资源;
捕获通用请求异常:开发时需捕获连接失败、超时、HTTP 状态码非 200等异常,避免单个请求失败导致整个程序崩溃,同时记录异常信息,便于后续排查。
通用请求发送伪代码(GET 方式,多语言通用逻辑):
plaintext
2.4 测试技巧:先单条后批量,减少调试卡壳
建议遵循 **“先单条测试,再批量开发”** 的原则:先用 Postman 做单条商品 ID 的调用测试,确认签名、参数、返回数据均正常后,再进行代码开发;代码开发完成后,先做少量 ID 的批量测试,确认批量调用逻辑无误后,再投入正式使用。
三、数据解析核心实操要点:高效提取,解决解析卡壳
接口调用成功后,部分开发者会卡在数据解析环节,比如嵌套字段提取失败、空值导致程序报错、批量数据解析效率低,本部分梳理电商开发中最常用的 JSON 格式数据解析要点,兼顾实操性与工程化。
3.1 核心解析原则:容错性优先,避免解析报错
淘宝商品详情 API 返回的 JSON 数据为标准化结构,核心分为「状态层」和「数据层」,解析的核心原则是 **“先判断状态,再提取数据,全程做非空判断”**,避免因商品下架、ID 无效、字段缺失导致解析报错。
先判断业务状态码:先解析返回数据的业务状态码(如 code=200 为成功),而非仅判断 HTTP 状态码,避免 HTTP 请求成功但业务调用失败的情况;
非空判断全覆盖:提取所有字段时均做非空判断,尤其嵌套字段(如店铺信息
shop_info下的shop_name),避免字段为null导致的解析异常;数据类型转换:对价格、销量、库存等数字型字段做类型转换,避免返回的字符串类型影响后续的数据分析与计算。
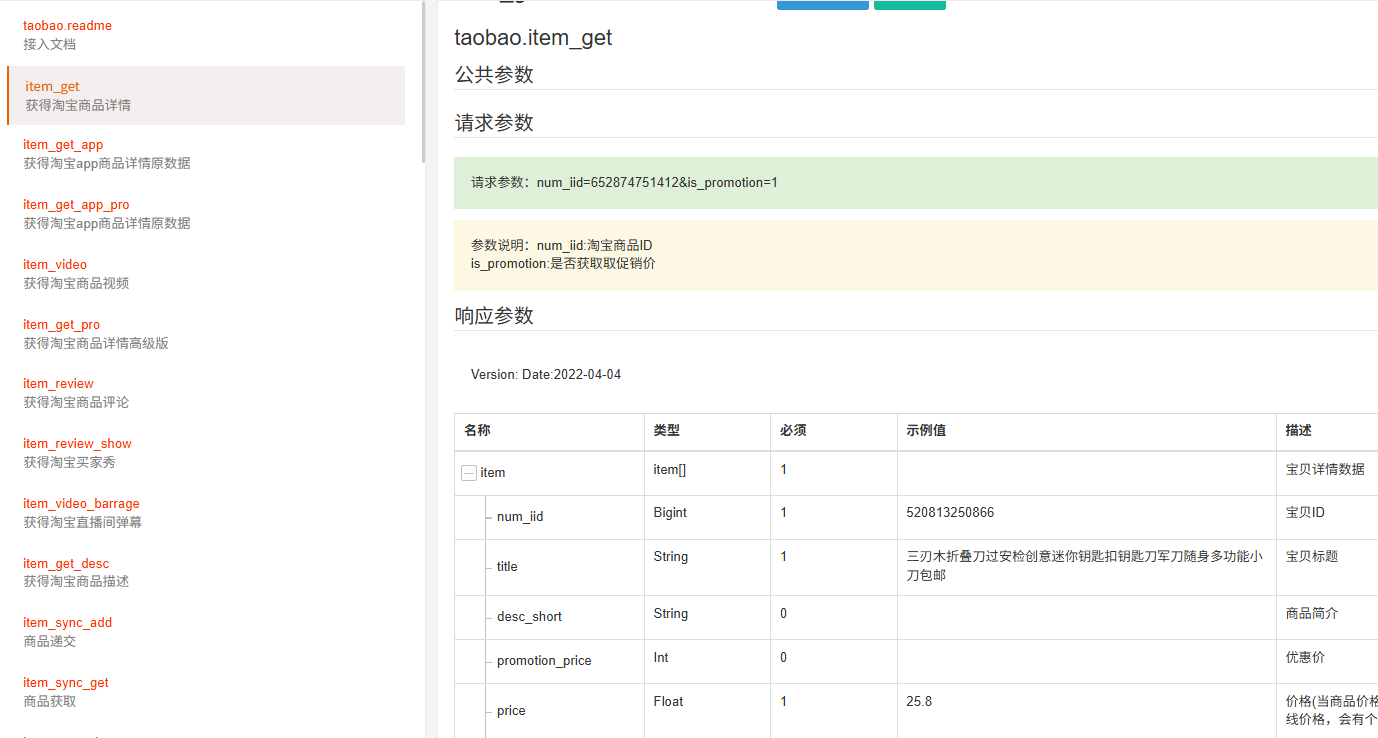
3.2 单条数据解析:提取核心字段,适配业务需求
电商开发中,商品详情的核心字段为商品 ID、标题、主图、实际售价、原价、销量、库存、类目、店铺信息,解析时可按需提取,以下为Python/Java 双语言简易解析示例,覆盖嵌套字段提取与非空判断,可直接套用。
Python 解析示例:
python
运行
Java 解析示例(使用 FastJSON):
java
运行
3.3 批量数据解析:高效遍历,避免批量处理卡壳
批量调用 API 时,返回的data字段为商品数据列表,解析核心是 **“遍历列表 + 单条解析逻辑复用 + 异常跳过”**:
直接复用单条数据的解析逻辑,避免重复开发;
遍历列表时,对单个商品的解析异常做跳过处理,避免单个商品解析失败导致整个批量任务中断;
对批量解析后的结果做数据去重、空值过滤,保证数据的有效性。
3.4 特殊解析问题:图片防盗链,解决资源获取卡壳
部分开发者解析出商品主图 / 详情图地址后,会卡在图片无法访问的问题,这是因为淘宝原生图片有防盗链机制,解决方案有 2 种,均为行业通用:
使用服务商提供的图片转存接口:正规服务商均会提供该接口,可将淘宝原生图片地址转为无防盗链的地址,直接访问;
自定义请求头:访问图片时,在请求头中添加合法的 Referer(如淘宝官网地址),绕过防盗链拦截。
四、对接后高频卡壳问题排坑要点:对症下药,快速解决
即使按上述要点开发,仍可能因细节问题出现卡壳,本部分总结对接过程中5 个最高频的卡壳问题,给出原因 + 精准解决方案,帮开发者快速排查,无需反复调试。
| 卡壳问题 | 核心原因 | 精准解决方案 |
|---|---|---|
| 签名验证失败(最常见) | 拼接顺序错、编码不一致、大小写不匹配、凭证错 | 1. 严格按文档拼接字符串;2. 统一使用 UTF-8 编码;3. 按要求转大小写;4. 验证凭证有效性 |
| 数据返回为空 / 字段缺失 | 商品 ID 无效、商品被风控、批量 ID 超限制 | 1. 验证商品 ID 是否有效(淘宝搜索确认);2. 风控商品联系服务商处理;3. 按限制拆分批量 ID |
| 图片地址无法访问 | 淘宝原生图片防盗链机制 | 1. 使用服务商图片转存接口;2. 访问图片时添加合法 Referer 请求头 |
| 调用频率受限 / 请求被拒 | 超出服务商的 QPS / 分钟调用量限制 | 1. 代码中添加频率控制(如 time.sleep);2. 多账号轮询调用;3. 向服务商申请提升限制 |
| 接口调用超时 / 连接失败 | 网络波动、服务商单节点故障、超时时间过短 | 1. 增加超时时间至 10-30s;2. 联系服务商切换备用节点;3. 增加请求重试机制 |
五、生产环境落地核心优化要点:工程化开发,避免线上卡壳
开发环境对接成功后,落地生产环境时,需做工程化优化,避免线上出现卡壳问题,梳理 4 个生产环境必备的优化要点,适用于企业级项目开发:
5.1 增加异常重试机制
对网络超时、连接失败、服务商临时节点故障等临时性异常,增加有限重试机制(如重试 3 次,每次间隔 1s),避免单次临时性异常导致业务失败;注意:对签名失败、ID 无效等永久性异常,无需重试,直接记录并跳过。
5.2 实现精细化频率控制
根据服务商的调用限制,在代码中实现精细化的频率控制,如 QPS=10 则控制每秒调用不超过 10 次,可使用令牌桶、漏桶算法,或简单的延时函数,避免因超出限制导致接口被封禁。
5.3 增加数据缓存策略
对高频访问、更新频率低的商品数据(如热销商品、类目商品),增加本地缓存 / Redis 缓存,缓存有效期设置为 10-30 分钟,减少重复的 API 调用,降低调用成本,同时提升数据获取效率。
5.4 完善日志与监控体系
日志记录:记录所有 API 调用的请求参数、返回结果、异常信息、调用时间,日志保存至文件或日志平台,便于线上问题的追溯与排查;
监控告警:对 API调用成功率、平均响应时间、异常率做监控,当调用成功率低于 99%、异常率高于 1% 时,触发短信 / 钉钉告警,及时发现并解决问题。
六、服务商选型核心判断要点:选对服务商,从根源减少卡壳
很多时候,对接卡壳并非开发者的问题,而是服务商的接口设计不规范、文档不清晰、节点不稳定导致的,因此选对靠谱的淘宝商品详情 API 服务商,是从根源减少对接卡壳的关键。结合实战经验,梳理5 个核心选型要点,帮开发者避开无良服务商的坑:
接口文档标准化:服务商需提供完整、清晰、无歧义的接口文档,包含凭证说明、签名规则、参数列表、返回示例、错误码说明,文档混乱会直接导致对接卡壳;
数据稳定性与完整性:要求调用成功率≥99%,数据实时同步淘宝平台,核心字段无缺失、无延迟,可要求服务商提供免费测试额度,实际验证数据质量;
技术支持响应快:正规服务商需提供7*24 小时在线技术支持(企业微信 / QQ / 电话),对接过程中出现卡壳问题,能快速响应并给出解决方案,避免无限期等待;
节点高可用:服务商需提供多节点部署,单节点故障时可自动切换,避免因节点故障导致接口调用中断,影响生产业务;
计费透明且灵活:优先选择按次计费 / 套餐制的服务商,无隐形消费、无套路扣费,对无效 ID、风控商品提供免费重调服务,批量调用有优惠,降低长期使用成本。
七、总结
淘宝商品详情 API 的对接并非复杂的技术工作,多数卡壳问题均源于细节忽略,比如签名规则理解错误、参数编码不规范、解析时未做非空判断,或选择了不靠谱的服务商。
本文梳理的全流程核心要点,本质是 **“标准化开发 + 容错性设计 + 精细化排查”**:对接前做好凭证与规则确认,调用环节严格遵循签名与参数规范,解析环节做好非空判断与类型转换,生产落地做好异常处理与监控,再配合靠谱的服务商,就能彻底解决对接卡壳问题,实现 API 的高效、稳定调用。
如果在实际对接过程中,还遇到签名生成、批量调用、生产优化等具体的卡壳问题,可在评论区留言,笔者会逐一解答;如需获取标准化的 API 对接示例代码(Python/Java/PHP),也可私信交流。
收藏本文,后续对接电商平台 API 时可直接参考,帮你节省大量的调试时间,专注于业务本身的开发与优化。